Large Language Models have become the talk of the town for their tremendous abilities to comprehend natural languages and complete sentences. These accomplishments of large language models are attributed to the architecture that they follow – Transformer Models. The transformer model is a type of neural network architecture that has gained significant popularity and revolutionized the field of natural language processing (NLP). It was introduced in the paper “Attention Is All You Need” by Vaswani et al. in 2017. Before exploring Transformer models any further, it is essential to revise Neural Nets.
Table of Contents
Why do we need Language Models?
“Necessity is the mother of invention”.
Every invention in the history of mankind stems from the idea of making life easier. From matchsticks to T-shirts, and from money as we know it, to languages that we are so proud of, we’ve constantly sought to simplify our lives. However, when work became monotonous for humans, we began programming machines to take on mundane tasks. Now that programming machines has become a cumbersome task in itself, we humans have endeavoured to invent a way to communicate with machines. This is where NLP comes in.
NLP or Natural Language Process is a branch of Artificial Intelligence that deals with the study and development of computational models and algorithms that enable computers to understand, interpret, generate, and manipulate human language in a meaningful way. Speaking of computers that can seemingly understand human queries and answer them in the most humane way possible, Tasks like Text-Classification, Sentiment Analysis, Machine Translation, Question-Answering, Information Extraction and Speech Recognition fall in the realm of Natural Language Processing.
The latest invention that has given mankind a certain level of mastery in the pursuit of “Talking to computers” is a class of Large Language Models (abbrev LLMs). Let’s understand more about these beasts of programs.
LLMs
Language models began as an attempt to predict the next word in a sequence of words through probabilistic analysis of the sequence. The analysis would take into account the frequencies of word occurrences and the pattern of their orientation in the sequence. This approach to establishing relationships amongst words in a sequence has been improved over time using neural networks and mathematical functions, thus raising a class of models called “Large Language Models”.
LLMs are advanced language models that use billions of parameters along with deep learning techniques to capture complex patterns and relationships amongst words in a sentence. They are a significant leap from their ancestors in scale, size, and processing abilities, thus allowing them to grasp the context of an entire sequence instead of relying on the context of a fixed window of words.
The number of parameters that these models use in their analysis allows them to capture rather complex patterns and relationships among words in the sequence. This contributes to an extremely important LLM behaviour – Generalized Understanding. They can generate contextually relevant text even for unseen or ambiguous input.
However, it is crucial to understand that the contextually relevant text may be unsuitable for usage on grounds of factual or political incorrectness; or any other such reason.
The major improvement of LLMs compared to previous language models is their ability to achieve generalised understanding, which has led to a wide range of applications for these highly energy-intensive programs. The achievement of this understanding can be attributed to factors such as architecture, training techniques, and the availability of large-scale datasets. In this document, we will explore the architecture of LLMs: Transformer Models, but before we do that, let’s do a brief review of neural networks.
Brief Revision of Neural Networks
- A neural network is a class of algorithms used to implement AI.
- The building blocks of a Neural network are called Neurons as they were modelled around biological neurons.
- Every neuron processes inputs using a defined mathematical function called the activation function.
- The connections between neurons and the flow of information are determined by the network’s architecture.
- Each neuron typically receives input from multiple neurons in the preceding layer and sends its output to multiple neurons in the subsequent layer.
- The neural network uses a probabilistic approach to solve the problem at hand.
Transformer Models – Introduction
Now that we have revised neural networks, we can move on to talk about Transformers. Transformers aka Attention Nets (as they were initially known), are primarily neural networks. But, they have been highly successful owing to their Encoder-Decoder architecture and the implementation of a self-attention mechanism.
Before we move any further, let’s try to describe what these models do in the most abstract terms to get an idea of what they do. So here goes:
💡 “This kind of Neural Network works by deriving relationships between sequential data, thus learning by context and inferring meaning from it.”
The Transformer models take sequential data as input and can process multiple elements of this data simultaneously [aka parallel processing]. The data elements that the neurons process are assigned weights wrt their relevance and importance in the input sequence. This is how transformers tend to “pay attention” to relationships between distant elements in the sequence. Now, as we swiftly move to the next topic, please note that methods of finding relevance or importance are pure mathematical functions or operations that we are not covering in depth.
Transformer Models – Architecture
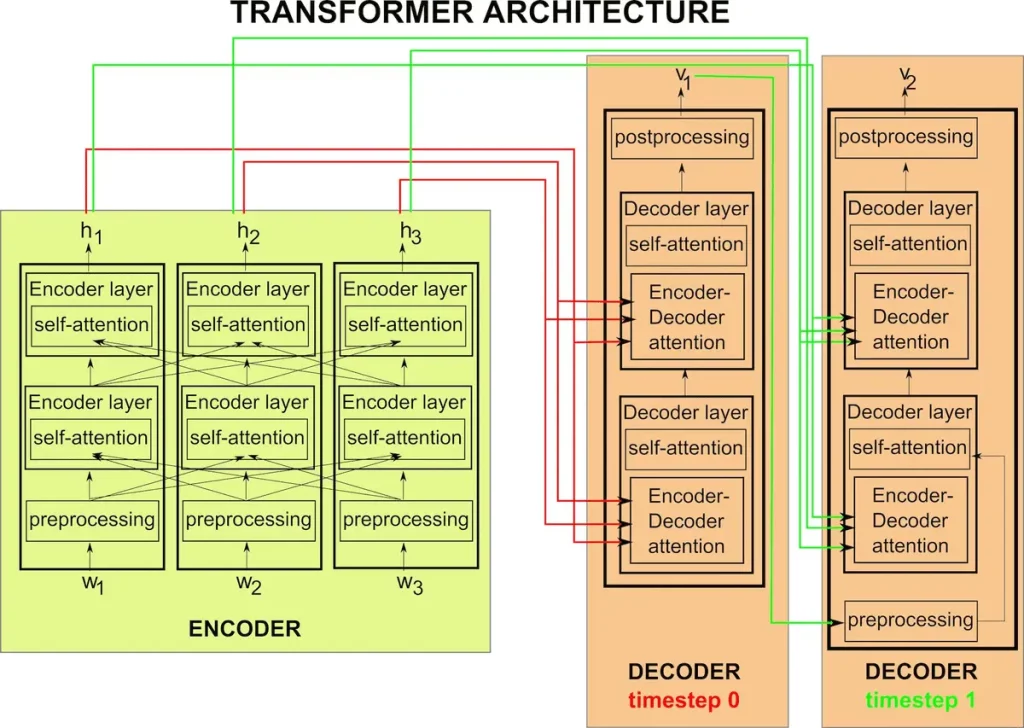
These Attention Nets are architected using Encoder and Decoder Models. Thus, they are similar to Autoencoder models in being able to learn without data labelling (unsupervised).
But it does require following a supervised learning approach for fine-tuning and becoming usable.
They are also similar to Sequence-to-sequence models in that they both use Encoder and Decoder for input-output sequence mapping.
It is now vital that we list down the components of Attention Nets.
- Encoder
- Self Attention layer
- Decoder
- Encoder-Decoder Attention layer
- Output Generation layer
💡 Let’s keep in mind that a token is representative of a single unit of an input sequence. It can be a word, a phrase, or a subword. It consists of multiple layers of self-attention mechanisms and feed-forward neural networks
Encoder
Simplistically speaking, the encoder does what its name says – encodes (along with processing the tokens). It is where we feed in the input sequence, which is treated as a sequence of tokens. The encoder is responsible for tokenising the input sequence and incorporating positional and contextual information about tokens into their representations. It captures the contextual information of each token by leveraging self-attention mechanisms and position-wise feed-forward networks within the encoder layers. The self-attention mechanism allows the model to attend to other tokens in the sequence, while the feed-forward networks capture complex relationships between words. The resulting contextual representations contain information about the token’s meaning within the given context.
Self Attention Layer
The “Self-Attention” feature sets Attention Nets apart from other neural networks that work on NLP. This layer is responsible for allowing the model to weigh the importance of different elements in the input sequence when processing each element. This enables the model to capture dependencies and relationships between distant elements in the sequence. It is lined alongside the multiple layers of encoders and decoders. This layer is intertwined with Encoder and Decoder layers.
Decoder
The decoder component of Transformer models generates an output sequence based on the processed input sequence. It also consists of multiple layers of self-attention mechanisms and feed-forward neural networks. Without going into the details of these sub-layers, we can briefly understand that the decoder generates the output sequence token by token. It does this by attending to the previously generated tokens in the output sequence and the encoded representations from the encoder. At each step, the model predicts the next token by considering the context of the previously generated tokens and the information from the input sequence.
Encoder-Decoder Attention
In addition to self-attention, Transformers employ encoder-decoder attention mechanisms. The decoder attends to the encoder’s output to capture relevant information from the input sequence. The purpose of this layer is to align the decoder’s generated output tokens with the relevant parts of the input sequence. It enables the decoder to selectively focus on different positions in the encoded input sequence to capture the relevant context.
Output Generation
The final layer of the decoder produces the output sequence, which could be a translation, a summary, or any other task-specific output.
The basic idea that ties all these components together is that the encoder takes in a sequence of tokens to encode with self-attention and passes on the output to the decoder. The decoder then uses self-attention data added by the encoder to decode the output of the encoder, simultaneously employing self-attention mechanisms to produce the output.
Transformer Models – Applications
- Machine Translation
Communication has tied the world together, yet the difference in language keeps us apart. To bridge the gap between communities and enable them to communicate, the art of translation was born. When this is done by a machine, then it is referred to as Machine Translation.
- Text Generation
Generating the next word, finishing a sentence for a user, preempting a user question, or answering it are all examples of Text generation.
- Sentiment Analysis
Understanding the context of a sequence of words well enough to be aware of the intent or sentiment with which it is spoken. Sentiment analysis on social media platforms is widely prevalent and helps brands gauge an understanding of the public’s opinion of their brand.
- Question Answering
This is a specific case of Text generation. Question-Answering has become the most sought-after application of LLMs today. The popularity of ChatGPT is testimony to this.
- Named Entity Recognition
This means recognising and extracting entities that are known in the public domain, say, dates, names of places, etc. This use case can be found in market research or information extraction.
- Speech Recognition and Synthesis
The ability of programs to understand speech by taking in audio-spoken input and converting it to text is called Speech recognition. Speech synthesis is the opposite of speech recognition. It is the process of converting text to speech. This is employed by all AI-based personal assistants, navigation systems, etc.
- Image Captioning
Describing an image is called Image captioning. This finds use in social media marketing.
Most LLMs are based on Transformer Models. Nevertheless, here are a few examples from the public domain that have been created on top of transformer models:
- Google Translate
- OpenAI’s GPT (Generative Pre-trained Transformer) series
- BERT (Bidirectional Encoder Representations from Transformers)
Please Note that the above-mentioned products are built following the transformer architecture. For instance, BERT is built on top of the Transformer Model Architecture. It can be thought of as an application of this concept called the Transformer Model. It specialises in language understanding and feature/representation learning. The bidirectional in its name tells us that it processes a given input sequence both from right to left and left to right to understand relationships between words in a sentence.
Where can you start with Transformers?
If you’re interested in experimenting with Transformer Models on your own, there are many resources available online that can help you get started.
For beginners, one of the best places to start is with the HuggingFace library. The library offers a large collection of pre-trained models and a course that is specifically designed for beginners. The course covers a range of topics, from the basics of NLP to advanced techniques for working with transformer models. Additionally, the HuggingFace library provides a variety of code snippets and tutorials that can help you quickly get up to speed on using transformer models in your own projects.
One of the most popular transformer-based models, BERT (Bidirectional Encoder Representations from Transformers), has been used for a variety of tasks, from text classification to question answering. BERT is an open-source project developed by Google, and there are many online resources available for learning and working with the model.
Another popular transformer-based model is GPT (Generative Pre-trained Transformer), which is developed by OpenAI. GPT has been used for a range of tasks, including text generation, and language translation. OpenAI has a chat-based interface to GPT to experiment with it, you can head here.
In addition to these resources, there are many other transformer-based models and tools available online that can help you experiment with NLP and transformer models. Whether you’re a beginner or an experienced developer, there are plenty of resources available to help you learn and grow in this exciting field.
Thanks for reading!
Further reading
If you’re interested in learning more about Transformer models, there are many resources available online. The HuggingFace library is a great place to start, with a large collection of pre-trained models and a course for beginners. Additionally, Google’s Transformer-based models, such as BERT and GPT, are widely used and have many resources available for learning and implementation.
You can also check out our post on an application of large language models in the customer service domain – Build a Revolutionary 100x Digital Customer Service Experience with Generative AI.
If you want to build a more customised application using open source and proprietary large language models, do read our post, Simple and Effective LangChain Guide to Get Started.


5 Comments
Ciasto na Pancake
Incredible article! You have a talent for explaining complex topics in a way that’s easy to understand. I really appreciated the examples you used. They helped me grasp the concepts much better. Keep up the great work!
Naszyjnik Lew
What a great post! Your points are well-articulated and backed by solid research. Impressive work!
best iptv uk
I just could not leave your web site before suggesting that I really enjoyed the standard information a person supply to your visitors Is gonna be again steadily in order to check up on new posts
Lot Balonem Polska
Your article was not only informative but also very well-written. You have a talent for communication.