Overview:
This blog delves into the evolution of HTTP with a specific focus on addressing head-of-line blocking (HOL), a well-known challenge in earlier HTTP versions. We’ll trace how each iteration of the protocol has improved on this front, culminating in HTTP/3. This latest version introduces robust mechanisms that greatly reduce the impact of HOL, marking a significant advancement in web communication, and setting a new standard in how efficiently data travels across the internet.
Head of Line Blocking
Before we explore the solutions implemented by various HTTP versions to address head-of-line blocking, it’s important to understand exactly what this term entails. Head-of-line blocking occurs in any scenario where a single stalled or delayed request in a network causes subsequent delays in the delivery of other requests within the same stream.
Consider This Example:
Imagine you’re downloading multiple files from a website over an HTTP/1.1 connection. You decide to download a large video file and several smaller image files simultaneously. The request for the large video file is processed first, and because HTTP/1.1 handles requests sequentially over the same connection, all the smaller image file requests must wait until the
the video file has been completely downloaded.
In this scenario, the video file request represents the stalled request causing delays for all subsequent smaller file requests queued behind it. Although the server is capable of sending the smaller files quickly, they remain queued and cannot be delivered until the larger file is fully transmitted. This results in noticeable delays, illustrating a classic example of head-of-line blocking.
In order to tackle the issue of head-of-line blocking, several improvements have been made in the evolution of HTTP.
HISTORY OF DIFFERENT HTTP PROTOCOLS
Let us understand how natively the initial version of the HTTP used to deliver data and how subsequent versions improved on this aspect.
HTTP/1
The initial version of the HTTP protocol utilised a straightforward request-response model. In this model, the client sends a request to the server and waits for a response. This approach was fundamentally sequential: only one request could be handled at a time. Once a request was fully processed and the response received, then—and only then—could the next request be initiated. This serial processing led to significant delays, especially with resource-heavy websites, as each resource (like an image or script) required a separate request and had to wait its turn.
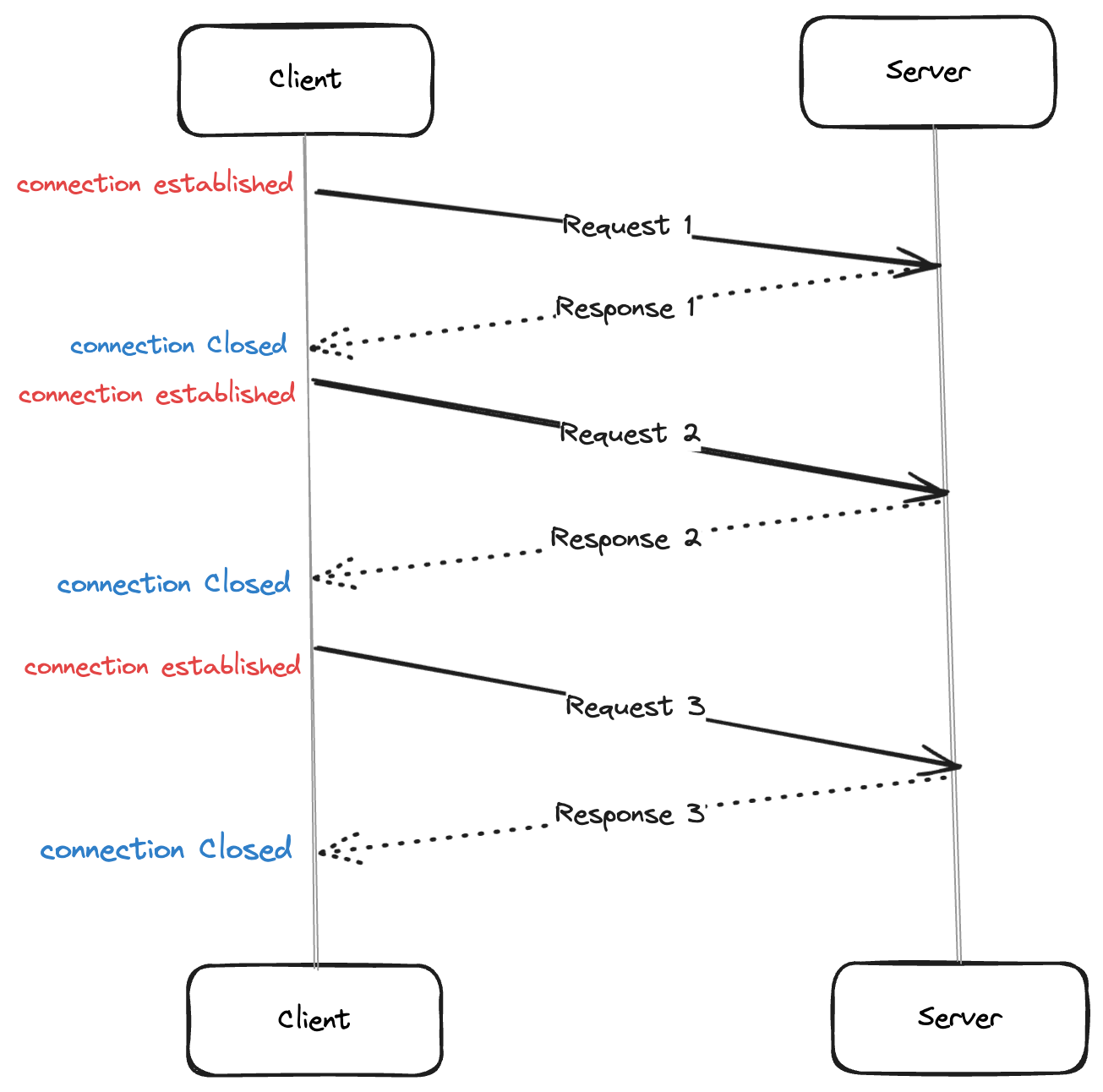
In HTTP/1.0, connections are closed after each request-response cycle by default. To improve page load times by keeping connections open for multiple requests, clients needed to explicitly add the Connection: keep-alive header. This was inefficient for complex or content-rich websites, resulting in slower response times. To overcome these drawbacks, HTTP/1.1 was introduced, which defaulted to persistent connections, eliminating the frequent need for the Connection: keep-alive header.
HTTP/1.1
HTTP/1.1 introduced the concept of keeping the connections alive by default,
which allowed multiple requests to be sent and received over a single connection. This helped in reducing the overhead of establishing multiple connections and improved the performance of web page loading.
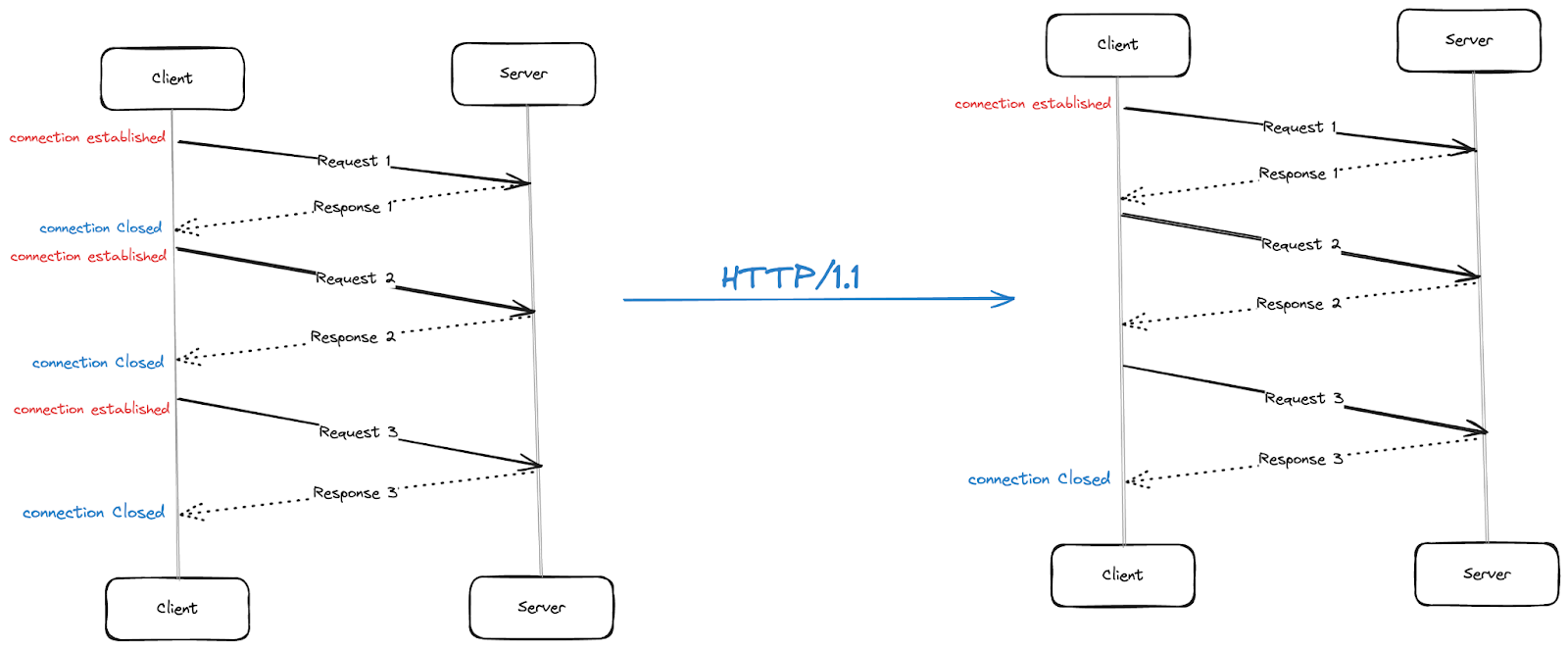
However along with keeping the connections alive HTTP/1.1 also introduced the concept of sending multiple requests over a single TCP connection, using the technique of PIPELINING.
PIPELINING
Pipelining in HTTP/1.1 allows a client to send multiple requests to the server without waiting for the first response, aiming to improve HTTP transaction throughput.
Requests are sent in rapid succession on the same TCP connection. However, the server is required to process these requests and issue responses in the order they were received.
Example of Pipelining
Consider sending requests for three resources (A, B, C) over a single connection. The client sends:
- Request A
- Request B
- Request C
The server must respond in this exact sequence:
- Response A
- Response B
- Response C
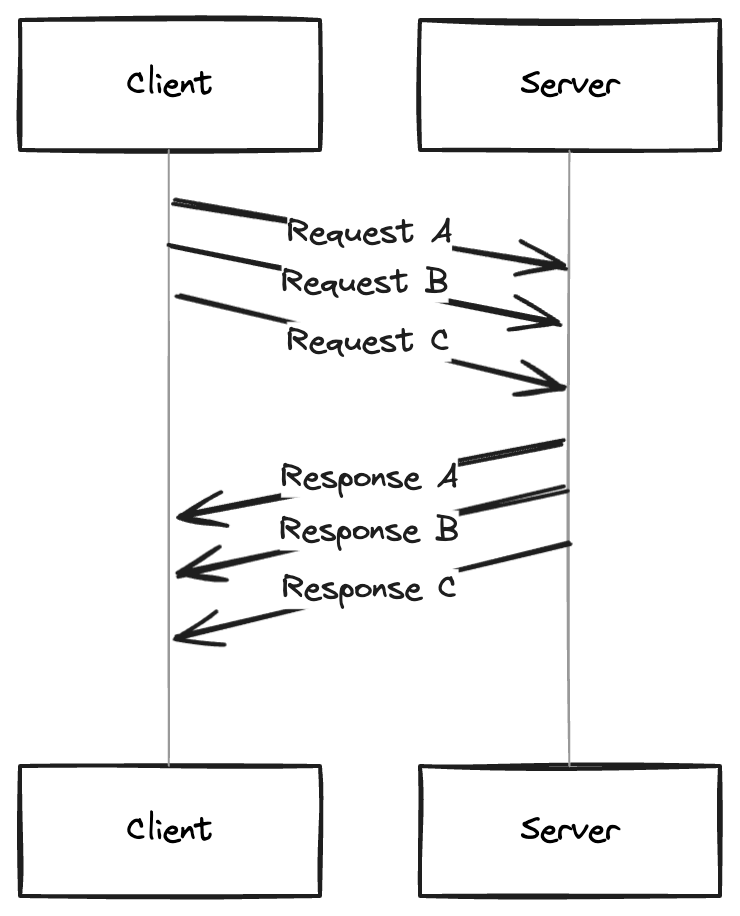
Key Limitation of Pipelining
The main limitation of pipelining is the strict order of responses. If a prior request (e.g., Request A) is slow to process, all subsequent responses are delayed. This ordering requirement can lead to significant head-of-line blocking, often negating the efficiency gains from pipelining.
This limitation led to the development of HTTP/2 introducing the concept of MULTIPLEXING.
HTTP/2.0
HTTP/2 introduced several advanced features over its predecessors, significantly improving how data is handled and transported over the web.
One of the main innovations of HTTP/2 is its approach to solving the head-of-line blocking (HOL) issue prevalent in HTTP/1.1, especially when pipelining is used.
Multiplexing: The Core Improvement
The key feature of HTTP/2 that addresses HOL blocking is multiplexing. Unlike HTTP/1.1, where requests and responses must be handled in sequence, HTTP/2 allows multiple requests and responses to be sent in parallel over the same connection.
This is achieved through a more complex but efficient system of frames that are part of a larger stream.
How Multiplexing Works
HTTP/2 breaks down the communication into streams, messages, and frames.
Frame:
In HTTP/2, the frame is the smallest unit of data, consisting of a fixed header of 9 octets that includes crucial information such as the stream identifier. This is followed by a variable-length payload that carries different types of data, like HTTP headers or body content.
Message:
A complete HTTP message, whether a request or a response, is composed of one or more frames. This structure allows messages to be broken down into smaller, manageable parts, facilitating more efficient processing and transmission.
Stream:
Streams represent the bidirectional flow of frames between a client and a server on a single connection. Key characteristics of streams include:
- Concurrency: Multiple streams can be open and active simultaneously on a single HTTP/2 connection.
- Bidirectionality: Both clients and servers can initiate frame transmission in any active stream, enhancing the dynamic exchange of data.
- Flexibility: Streams can be used exclusively by one party or shared between the client and the server, and they can be closed by either endpoint when no longer needed.
- Identification: Streams are uniquely identified by integers, which are assigned by the party initiating the stream.

The introduction of stream identifiers is particularly pivotal. Each frame is tagged with a stream ID, allowing for multiple requests and responses to be interwoven within a single connection. This multiplexing capability is the critical innovation in HTTP/2 that mitigates HOL blocking at the HTTP layer by eliminating the need for requests and responses to be processed in strict sequential order.
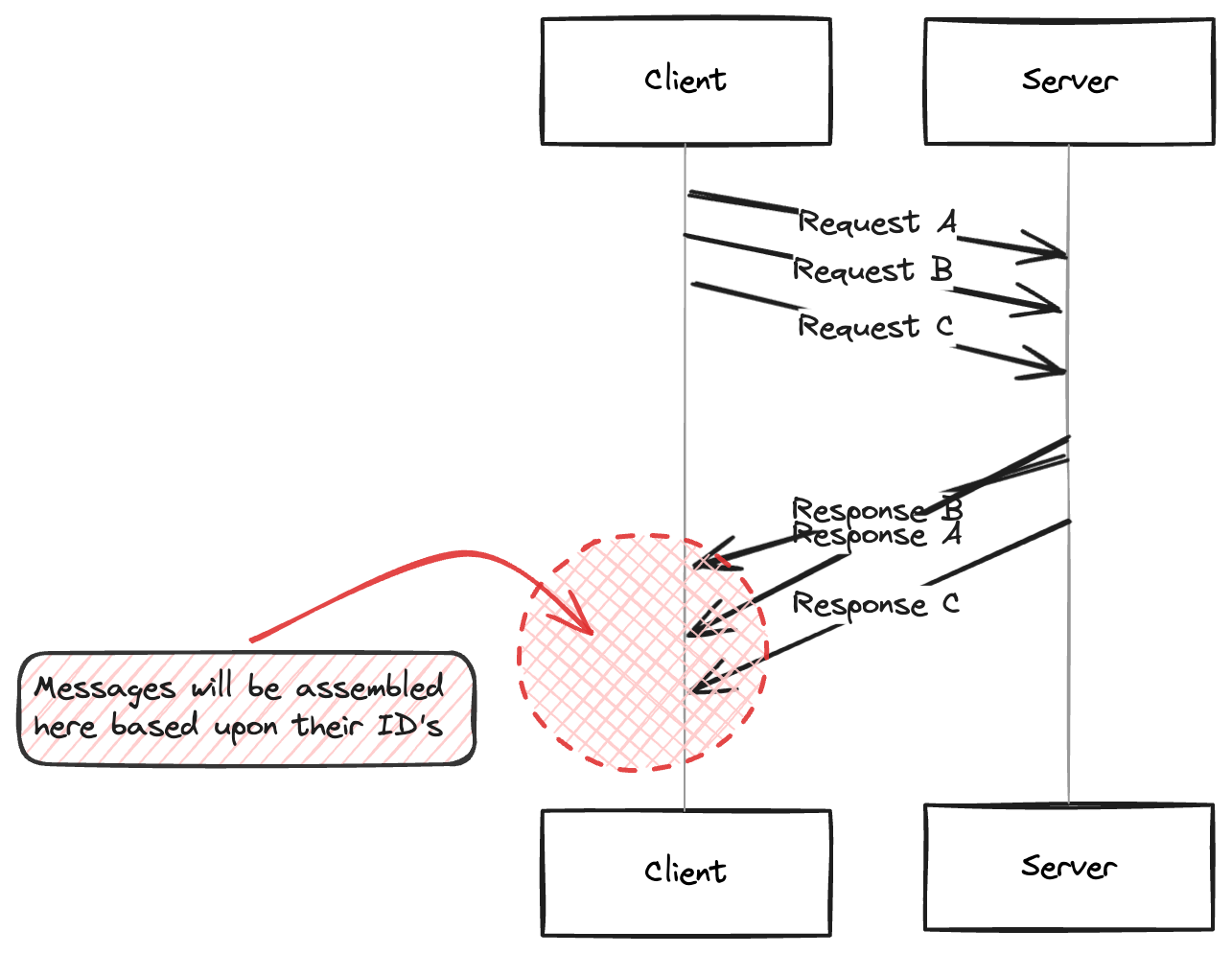
Example of HTTP/2 Multiplexing
Imagine a client sends requests for three resources—A, B, and C—almost simultaneously over a single connection. In HTTP/2:
The client sends three separate streams of frames: one for each request.
The server processes each stream independently. If the response for resource B is ready before A, it can send back B’s frames followed by A’s and C’s, without having to wait for A to complete.
This allows the server to utilise the connection more efficiently and reduces latency dramatically, as resources are delivered as soon as they are processed.
Benefits Beyond HOL Blocking
HTTP/2’s design not only addresses head-of-line blocking but also introduces other improvements:
Header Compression: HTTP/2 uses HPACK compression to reduce header size, which decreases the overall latency and bandwidth usage.
Server Push: This feature allows servers to proactively send resources to the client that it knows the client will need, further optimising the interaction.
LIMITATION OF HTTP/2.0
- TCP Head-of-Line (HOL) Blocking: HTTP/2.0 experiences delays known as TCP head-of-line blocking, which occurs within the TCP layer.
- Packet Sequence Requirement: Each TCP packet must be received in a specific sequence due to assigned sequence numbers. If any packet is lost, subsequent packets are stalled.
- TCP Buffer Holding: Lost packets cause subsequent packets to wait in the TCP buffer until the missing packet is retransmitted and received.
- Impact on HTTP Layer: The HTTP layer, built on top of TCP, does not handle these TCP retransmissions. It only notices a delay when attempting to retrieve data from the socket.
- Inability to Process Received Data: Even if received packets contain a complete HTTP request or response, they cannot be processed until the lost packet is retrieved.
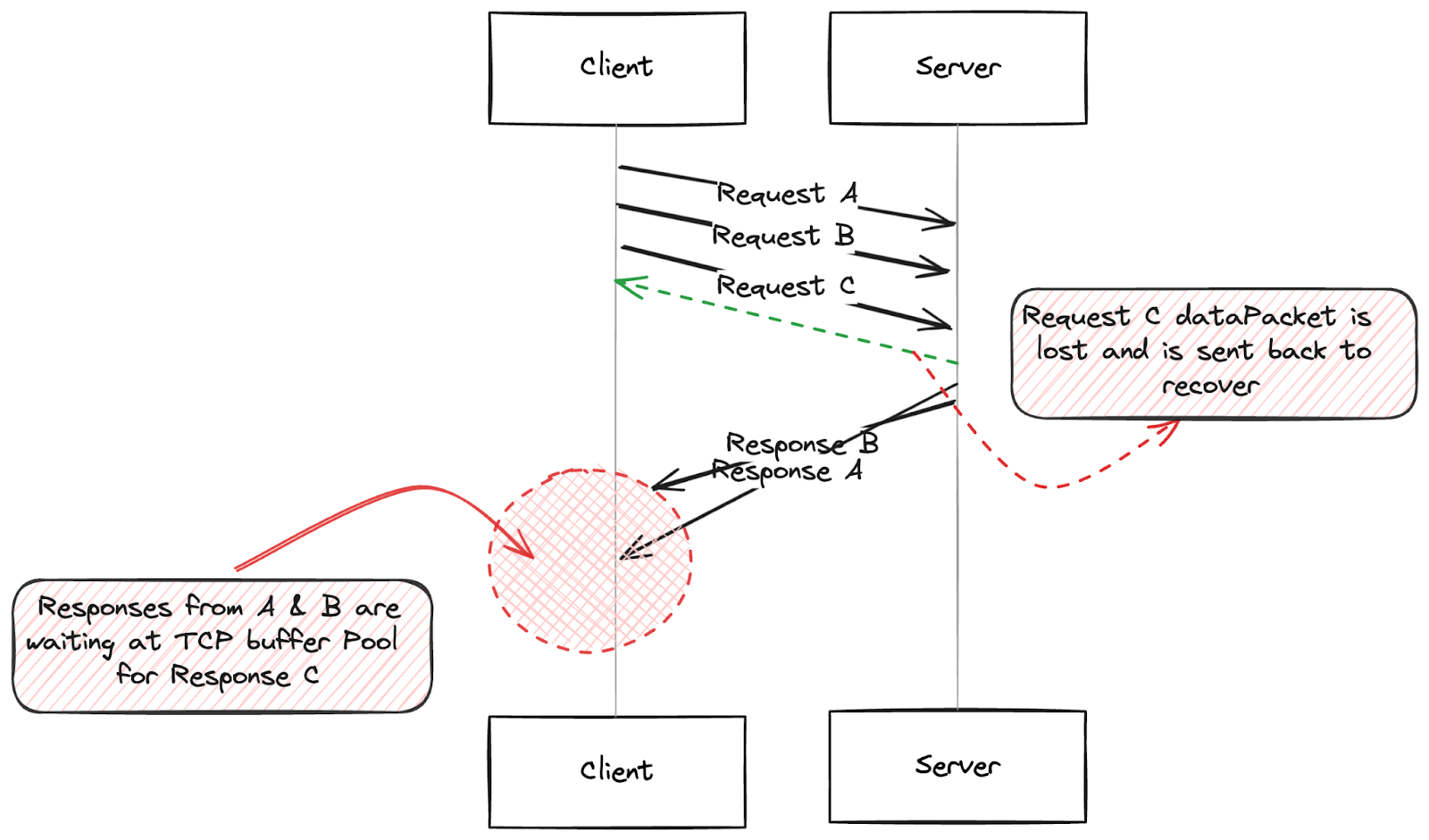
- Overall Connection Performance: A single lost packet can impact the performance of the entire TCP connection, highlighting HTTP/2.0’s dependency on the underlying TCP protocol.
And, this limitation of the HTTP/2.0 led to the development of the HTTP/3.0 or QUIC Protocol which leverages the UDP (User Datagram Protocol) protocol instead of the TCP to transfer the data,
HTTP/3.0
Building on the experiences and challenges faced with previous versions, HTTP/3.0 introduces a significant shift in how data is transmitted over the web, using the QUIC protocol to overcome the limitations of TCP as it utilises the UDP under the hood.
QUIC
The QUIC protocol, initially proposed as the acronym for Quick UDP Internet Connections, now only QUIC represents a significant advancement in internet communication technology. Its development and implementation have aimed to make the Internet faster, more secure, and more efficient.
History and Development
QUIC was originally designed by Jim Roskind at Google and was first implemented in 2012. The protocol was introduced as an experiment within Google’s Chrome browser to accelerate the loading times of web pages and to improve the overall performance of internet applications. Google publicly announced QUIC in 2013 and began to deploy it widely across its services, including YouTube and Google Search.
The interest in QUIC’s potential led to its adoption by the Internet Engineering Task Force (IETF) for further development and standardisation. The IETF formed a working group in 2016 to refine the protocol, which culminated in the publication of QUIC as a standard in May 2021, specifically as RFC 9000.
How HTTP/3 works
1. Independent Stream Multiplexing
In HTTP/2, streams of data are multiplexed over a single TCP connection. However, TCP ensures that data packets are received and processed in the order they are sent. If a packet in one stream is lost, TCP requires that this packet be received and acknowledged before any subsequent packets can be processed. This causes a delay for all streams, not just the one experiencing packet loss, leading to HOL blocking.
QUIC changes this by handling each stream independently at the transport level. It uses UDP as its basis, which unlike TCP, does not inherently require ordered packet delivery. QUIC implements mechanisms for order and reliability at the stream level, not across all streams. This means:
- Each stream is essentially an independent entity within the same QUIC connection.
- Lost or delayed packets in one stream do not block the processing of packets in another stream. Each stream handles packet loss independently, requesting retransmissions of its missing data without affecting others.
2. Smarter Packet Transmission and Loss Detection
QUIC improves on TCP’s mechanisms in terms of how efficiently it can detect and recover from packet loss:
- Selective Acknowledgments: QUIC uses selective acknowledgments that allow the receiver to inform the sender exactly which packets have been received. This allows the sender to retransmit only the lost packets, rather than everything following a lost packet as in TCP.
- Faster Retransmission: QUIC incorporates more nuanced time-based loss detection algorithms, which can trigger retransmissions more quickly compared to the traditional TCP retransmission timeouts.
3. Connection Migration and Path Probing
One innovative feature of QUIC is its ability to maintain a connection even when network conditions change (e.g., switching from Wi-Fi to cellular data). This is facilitated by:
- Connection Identification via Connection IDs: QUIC connections are identified by connection IDs rather than by the tuple of IP addresses and ports. This means that if a client changes networks, the connection can continue uninterrupted, as the server can still recognize the incoming packets as belonging to the same session.
- Path Probing: QUIC actively probes new network paths to check their viability before sending significant amounts of data. This ensures stability and reduces the likelihood of packet loss when network changes occur.
4. Stream Prioritization
QUIC allows for streams to be prioritised, which means that more important data can be sent and processed earlier than other streams, regardless of the order in which streams are established or packets are received. This flexibility improves the efficiency of data transmission, particularly in scenarios where resources need to be loaded in a specific order for optimal performance (e.g., loading a web page).
These mechanisms collectively allow HTTP/3 to utilise QUIC effectively to overcome the HOL blocking and other limitations seen in HTTP/2, leading to more efficient, reliable, and faster data transmission over the web.
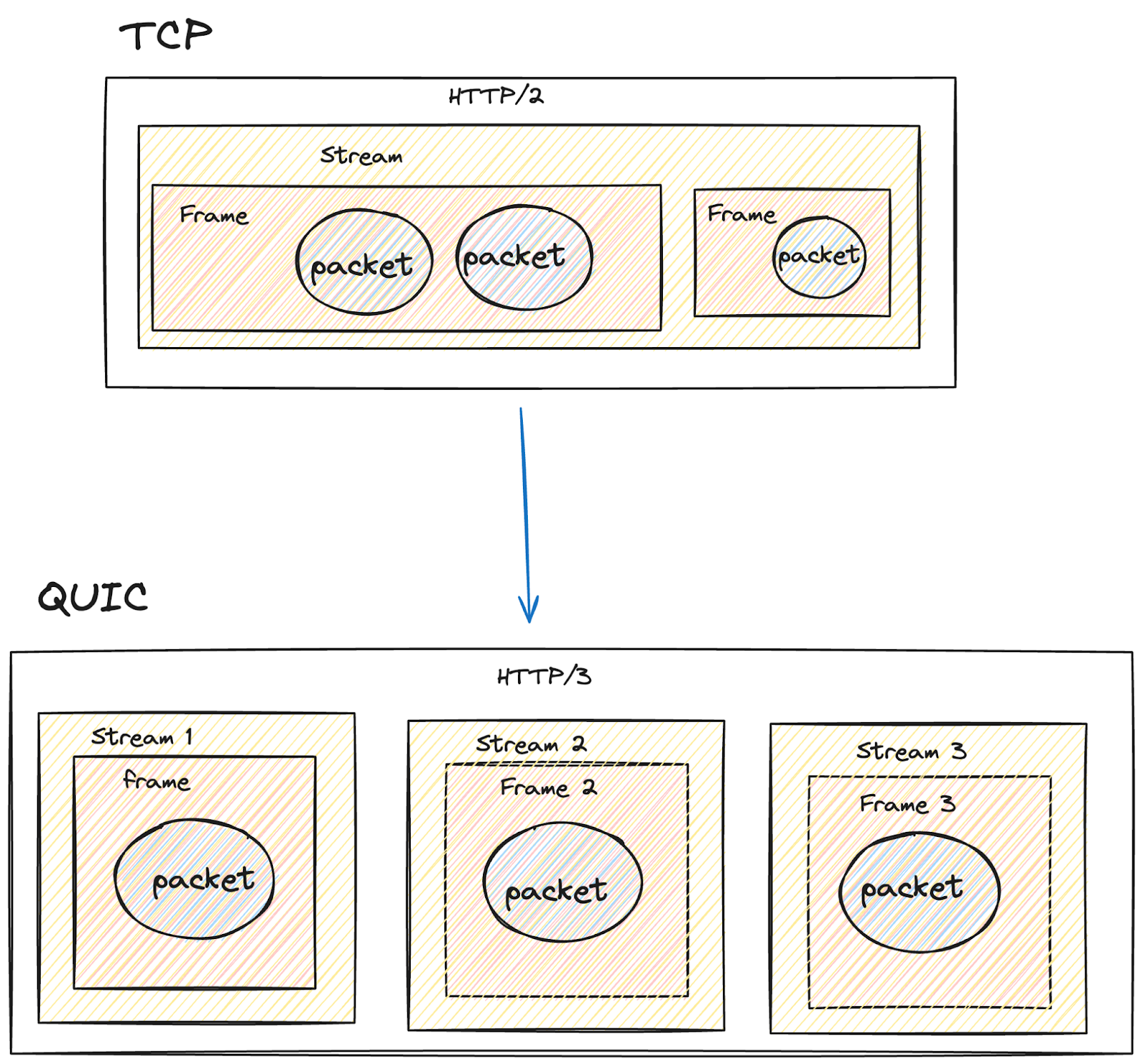
In the image above, within the HTTP/3 layer, if a packet is lost, only that particular stream has to wait, while another can continue until completion. This is unlike HTTP/2, where there is only one stream, so in the event of a loss, the entire data stream must wait.
To summarise all of this we can use the image below xD

Looking a Step Ahead
The question arises, is this the perfect end for the development of the HTTP protocol with the introduction of HTTP/3? While HTTP/3 provides significant improvements over its predecessors, it is not without its challenges and limitations. These issues not only guide current implementation efforts but also pave the way for what could be addressed in future versions, such as HTTP/4.0.
Current Challenges Facing HTTP/3:
- Widespread Adoption: One of the major hurdles for HTTP/3 is its adoption across the web. Due to its reliance on QUIC, which itself requires significant changes in network infrastructure and server software, deployment can be more complex compared to protocols based on TCP. This complexity could slow adoption rates.
- Network Compatibility: QUIC is built on top of UDP, which, although beneficial for speed and multiplexing, is not traditionally optimised for large-scale content delivery across all types of networks. Some corporate and public networks block UDP traffic due to security policies or legacy configurations, which could limit the effectiveness and reach of HTTP/3.
- Resource Usage: Initial studies and implementations have suggested that QUIC may require more computational resources than TCP, particularly because of its continuous encryption and connection management. This could increase costs for servers handling large quantities of connections, affecting scalability.
- Fallback Mechanisms: While HTTP/3 aims to gracefully fall back to HTTP/2 in scenarios where QUIC cannot be used, managing these transitions can introduce complexity and potential points of failure in network systems. Ensuring smooth transitions and compatibility with older protocols remains a technical challenge.
Considerations for HTTP/4
Given the existing and potential challenges of HTTP/3, future protocol developments could focus on:
- Enhanced Network Compatibility: Future versions could aim to improve compatibility with a wider range of network types and configurations. This might involve optimising how the protocol handles different network constraints or developing more robust methods for dealing with UDP restrictions.
- Resource Efficiency: Further optimising the protocol to reduce the computational overhead could be a major focus. This could involve refining encryption methods, stream management, and data transfer algorithms to reduce server load and improve energy efficiency.
- Hybrid Transport Mechanisms: Investigating the potential for hybrid protocols that can dynamically switch between UDP and TCP-like characteristics based on network conditions could offer a flexible solution that maximises performance and reliability.
- Improved Security Features: As cyber threats evolve, so too must the security features of network protocols. HTTP/4.0 could incorporate advanced security features to tackle emerging security challenges, ensuring data integrity and privacy.
- Automation in Configuration and Optimization: To ease deployment and operation, HTTP/4.0 could include more automated configuration and optimization features, helping systems to self-adjust based on real-time performance data and security threats.
As the web continues to evolve, so will the requirements and expectations for HTTP protocols. Each iteration aims not only to address the shortcomings of its predecessors but also to anticipate future needs, ensuring the web remains robust, efficient, and secure.
Read more about Shuru blogs here


13 Comments
Ashish
Awesome
Helped me a lot to understand the tech.
Ashish
Was very helpfull and informative.
Shivam
Very informative, thanks
Mansi
very insightful and creative 👏🏽
Shristi Singh
Informative and creative.. helped a lot .. ☺️
Dr.Dang
informative
Kasha
Hi, this weekend is nice for me, ffor the reason that this time i am reading this great educational pirce of writing
here at my residence.
acheteriptvabonnement
I do believe all the ideas youve presented for your post They are really convincing and will certainly work Nonetheless the posts are too short for novices May just you please lengthen them a little from subsequent time Thanks for the post
itsrider
helloI like your writing very so much proportion we keep up a correspondence extra approximately your post on AOL I need an expert in this space to unravel my problem May be that is you Taking a look forward to see you
tlover tonet
I’m commenting to let you understand of the cool discovery my daughter undergone browsing your web site. She discovered too many issues, which include what it is like to possess an awesome teaching spirit to let many others without problems understand several complex topics. You actually exceeded my expectations. Thank you for providing the informative, trusted, educational and fun tips on that topic to Sandra.
tlover tonet
I truly enjoy looking through on this web site, it has wonderful posts.
streameastweb
Fantastic site Lots of helpful information here I am sending it to some friends ans additionally sharing in delicious And of course thanks for your effort
streameastweb
I have read some excellent stuff here Definitely value bookmarking for revisiting I wonder how much effort you put to make the sort of excellent informative website