Automated deployments with AWS CodeDeploy can be a high-yielding CI/CD process. With good deployment automation, you can ensure that the team is always focused on solving the most pertinent problems and is not afraid of deployments. When things are manual, there is a high chance of making mistakes, and these mistakes are bound to happen. Why this is even more troublesome because when mistakes will happen, it will create fear in the deployment team which will impact the team’s delivery.
Continuing with our previous blog posts where we explained the possible git workflow solutions for a streamlined workflow of managing releases, we will discuss connecting your git hosting with your infrastructure to automate deployments below. We are going to specifically focus on using Bitbucket pipelines and AWS hosting.
Table of Contents
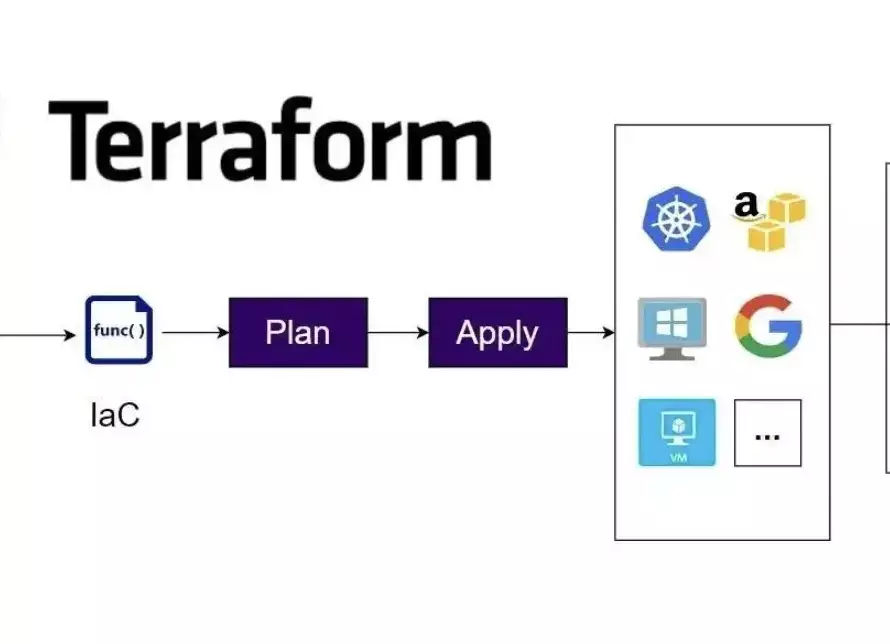
What is AWS CodeDeploy?
AWS CodeDeploy is a fully managed service that automates software deployments on infrastructure hosted at AWS to a variety of compute services, such as Amazon Elastic Compute Cloud (EC2), Amazon Elastic Container Service (ECS), AWS Lambda, and your on-premises servers. CodeDeploy can be used to deploy a nearly unlimited variety of application content, including:
- Code
- Serverless AWS Lambda functions
- Web and configuration files
- Executables
- Packages
- Scripts
- Multimedia files
How does AWS CodeDeploy work?
Although it supports deployment across a few products on AWS, we are primarily going to talk about just deployments across VMs. How it works is that you can create a new deployment Object from the AWS console and provide a tag on which codeDeploy should do the deployment. Follow the steps below to quickly set it up.
- Open code Deploy on AWS console
- Create a new deployment Object
- For staging and production tag your VMs with different values of the same tag. Let’s say your tag name is code-deploy, so you can tag staging and production VMs like this
1code-deploy = staging-service2code-deploy = production-service
- Here, service can be the name of your service. So if your service name is order-management, your tags can look like this
1code-deploy = staging-order-management2code-deploy = production-order-management
What this will do is, create 2 separate deployment flows for your staging and production VMs. Now moving on to, how we connect this with the Bitbucket Pipelines
What is Bitbucket Pipelines?
Bitbucket provides its deployment automation pipelines out of the box. You can read more about it on the official support page of Atlassian. You can add your test stage, packaging and deployment stages as well. It supports branch-specific stages as well.
Select a Base Image
The pipeline runners use docker containers to run and support the pipelines, so you can choose your language-specific docker image to begin with. For example, if you use JRuby, then your first line in bitbucket-pipelines.yml will be 1image: jruby:9.3.3.0
Configure Tests scripts
You can run any scripts in the pipelines. So running tests in the pipeline here is just about setting up the environment and dependencies in the right way and then triggering the test scripts.
Bitbucket pipelines support services, like Postgres, Redis etc, which also run on different containers and are made available as a service in the pipeline container. So your test stage can look something like the below, assuming you use Postgres to store test data:
- step:
name: Test
script:
- #install any dependency with apt, if any
- #run your test command
services:
- postgres
Code language: YAML (yaml)An Overview of Artifacts & their Role in automated deployment
Artifact is the code package that you will want to deploy on your servers. If you’re following a manual process, this step might not exist for you, in cases where you might be just going git pull on the servers 🙈
There are 3 parts to managing artifacts in your deployment automation process
- Creation of the artifact from your CI pipeline
- Storage of the artifacts in a secure way
- Deployment of the artifacts from your artifact storage to your servers
For the first one and second, creation of artifacts, you can add a simple step in your Bitbucket pipelines to create and store your artifacts. You can read more about it on the Atlassian official support page.
The way you decide to do step 3, is however going to impact the way you are going to do above 2 as well. Because how you choose to deploy means that you need to define your access to your artifacts, and that means it impacts how and where you store your artifacts.
To make sure, that our deployment works with AWS CodeDeploy, we need to make sure our artifacts are stored somewhere the CodeDeploy can access and S3 works perfectly here. Integrate your upload-artifact CI step to create a package and upload it to S3, you can read about this on this BitBucket repository. Make sure you create a zip file of the package because CodeDeploy only works with zip files.
Once the zipped code package is uploaded, we can use the package in the next step for our deployment.
How to set up automated deployment?
There are 2 steps now left to make our deployment work.
- Update the
bitbucket-pipelines.ymlto include the deployment step using the same aws-code-deploy image - Add an
appspec.ymlfile which is required by CodeDeploy to understand your deployment requirements.
Let’s discuss the second step here. appspec.yml is a helpful and efficient way to make you control your deployment. It can look like the following
version: 0.0
os: linux
files:
- source: /
destination: /var/opt/order_management
hooks:
ApplicationStop:
- location: deployment_scripts/stop_service.sh
timeout: 300
runas: ordermanagement
AfterInstall:
- location: deployment_scripts/setup_env.sh
timeout: 300
runas: ordermanagement
ApplicationStart:
- location: deployment_scripts/start_service.sh
timeout: 300
runas: ordermanagement
Code language: YAML (yaml)As you can see, there 2 major sections here that we are using, files & hooks. The files section helps CodeDeploy to understand where should it install the package which it has fetched from S3.
The hooks section is what gives us control over our deployment. Things like fetching application configuration, running database migrations or starting and stopping your service to make sure inflight requests are correctly served, all these use-cases can be easily covered by these hooks. You can read more about it on the official AWS CodeDeploy Documentation.
1 Comment
one hour mail
I couldn’t help but be enthralled with the basic information you offered about your visitors, so much so that I returned to your website to review and double-check recently published content.