The exploration of feasible Claude Code alternatives
Introduction
Shuru Labs has been continuously experimenting with ways to enhance developer productivity through developing data-driven, actionable frameworks, that increase the inclusion of AI tools in developer workflows.
This article captures my exercise in evaluating different avenues to locally run large‑language‑model (LLM) chatbots, without relying on proprietary services such as Anthropic’s Claude‑Code. While Sonnet-4 and Claude Code have proved invaluable, Claude Code’s variable usage limits aren’t very dependable (10-40 message requests every 5 hours, further subjected to spot-pricing). And the usage pressure on Anthropic’s infrastructure also brings the risk of service outages.
Hence, as a possible alternative (or backup), I’ve explored and compared several GPU‑as‑a‑Service (GaaS) providers, free research notebooks, and token‑based inference platforms, and thereafter, further experimented with self‑hosting an LLM on my local single‑GPU workstation.
Platforms Explored
| Platform | Category | Key Point |
| Runpod | GPU Cloud | Per‑second billing |
| Paperspace | GPU Cloud | VS Code plug‑in for Paperspace machines |
| TensorDock | GPU Marketplace | Spot‑style pricing |
| Kaggle | Research Notebook | Free but quota‑limited |
| Groq | Token API | Ultra‑low latency |
1. Runpod – GPU Cloud
- Category: On‑demand GPU rental.
- Cheapest 16 GB GPU (RTX A4000) at ≈ $0.09 / hour on Community Cloud and $0.25 / hour on standard nodes.
- Per‑second billing, 30+ regions, good Docker support.
- Pricing options at Runpod:

2. Paperspace (DigitalOcean)
- Category: On‑demand GPU rental.
- RTX A4000 16 GB is listed around $0.80 / hour (July 2025 data).
- Tight VS Code integration (but higher hourly rates than Runpod/TensorDock).
- Paperspace also has a VS Code extension to facilitate cloud machine management directly from the IDE.

3. TensorDock – Marketplace Style GPU Cloud
- Category: GPU marketplace.
- RTX A4000 16 GB from ≈ $0.10 / hour. RTX 4090 24 GB from ≈ $0.35 / hour.
- Great option if the lowest prices are desired and spot‑style variability isn’t an issue.
- TensorDock provides a rich comparison matrix between various models (along with hourly pricing) for quick reference as well:

4. Kaggle Notebooks
- Category: Free research notebooks.
- Free Tesla T4 or P100 GPUs (16 GB VRAM) with a 30 GPU‑hour weekly cap and 9‑hour max session.
- Quotas make it impractical for uninterrupted fine‑tuning, but perfect for quick experiments.
5. GroqCloud – Tokens‑as‑a‑Service
- Similar to OpenRouter.
- Category: Token‑based inference API (no raw GPU access).
- Example pricing (Aug 2025):
- Qwen3‑32B: $0.29 / M input tokens, $0.59 / M output tokens.
- DeepSeek‑R1‑70B distill: $0.75 / M input.
- Amazing throughput (LPUs), but not applicable for custom model weights or offline work, hence irrelevant to this study.
- While not relevant to our raw model bootstrapping experiment, GroqCloud’s playground offers a Google AI studio like dashboard with the OpenRouter style token-based pricing.

Glossary
A brief explanation of some technical terms that would come right ahead:
| Term | Definition | Implication for LLM Hosting |
| Quantization | Compressing model weights to lower precision.(For example, 4‑bit quantization). | Cuts VRAM requirement by 40‑60 %.Allows smaller GPUs to host bigger models at a manageable accuracy cost. |
| FP16 | Half‑precision 16‑bit floating‑point format. | Baseline on NVIDIA GPUs. Halves memory in comparison to FP32, but still heavy for large models. |
| VRAM Footprint | The total GPU memory used by weights, activations, and KV‑cache. | Hard ceiling on model size – when exceeded the process goes out-of-memory (OOM), leading to a crash/the OS killing it. |
| Context Window | Maximum tokens the model can attend to in a single pass. | Longer windows need more memory and time. Context windows hence limit prompt lengths. |
| LoRA | Low‑Rank Adaptation fine‑tuning technique. | Allows cheap fine‑tuning with tiny adapter weights that can be swapped in/out. |
| Token API | Cloud services that charge per input/output token (e.g., Groq, OpenRouter). | While they could be faster and not have scalability concerns, raw GPU access and custom weights aren’t available. |
| Spot Pricing | Dynamic rental rate that fluctuates with supply/demand. | Cheaper cost per hour, but with a risk of instance pre‑emption or sudden price spikes. |
| GPU Marketplace | Platform aggregating third‑party GPU hosts (For example: TensorDock). | Wider inventory and lower prices, but host quality can vary. |
| GGUF / EXL2 | Efficient file formats for quantized checkpoints. | Loads instantly in Llama.cpp / text‑gen‑webui saves disk space. |
| Inference Tokens | Tokens processed while the model receives or generates text. | Determines compute cost and overall latency. Batching reduces per‑token cost. |
The Self‑Hosting Experiment
I repurposed my gaming rig with an Nvidia RTX 4080 16 GB (≈ 48 TFLOPS FP16, 716 GB/s bandwidth), to see if I could serve a lightweight coding assistant locally.
The Model Selection Journey
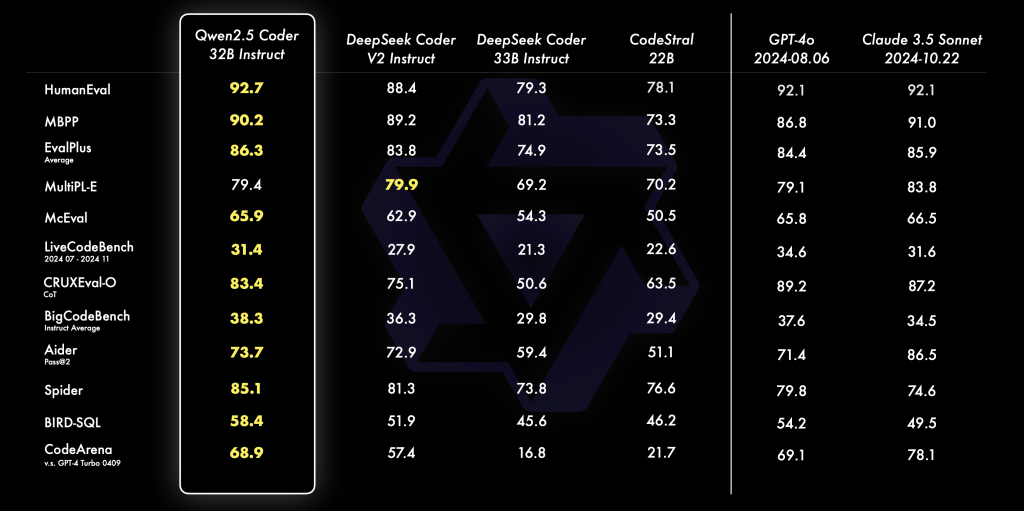
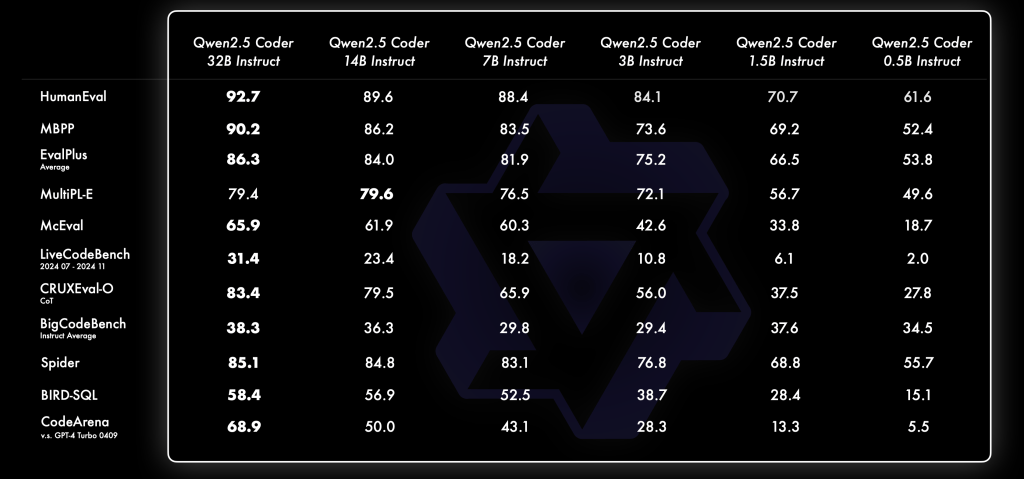
- While I originally wanted to test Qwen 2.5 Coder 32B Instruct, even with an SLI setup, this open-weight, flagship, code-oriented model will be well out of reach without a 64 GB VRAM GPU. This follows a generalized rule-of-thumb:
Rule‑of‑thumb: FP16 models need approximately 2x the LLM parameter‑size of GPU VRAM.
- So, as an alternative, I decided to try the Qwen 2.5 coder 7b instead, as its requirements were (theoretically) matched much better by the RTX 4080.
- However, the 15GB FP16 footprint from Qwen 2.5 coder 7b left no headroom, and my notebook would crash on the model mounting cell before proceeding to the next one.
- Hence, I decided to switch to the safer Qwen 2.5 coder 3b. And if that wouldn’t work either, the even safer DeepSeek‑Coder 1.3B Instruct – with approximately 6GB (3GBs for DeepSeek) FP16, hence stable with lots of VRAM to spare for context windows, as well as replicable on consumer GPUs and shared usage platforms (such as Kaggle).
- Plan: Using Qwen 2.5 coder 7b by quantizing to 4 bits, to squeeze larger context or multi‑query attention.
Making an OpenAI-compatible chatbot API using FastAPI and ngrok
As an extra addition, to make my LLM-setup usable across the network (the LLM running on my workstation and my work laptop using it over the LAN), or even across the internet, I decided to write an Open-AI compatible chatbot API, so that Agents compatible with the OpenAI V1 standard https://platform.openai.com/docs/api-reference/introduction, (such as Roo Code/CLine) running on other computers, may also utilize this LLM setup, a la OpenRouter style. The exposed endpoint URL was reachable via an ngrok tunnel, which I could share with my teammates as well.
Link to my python notebook: https://github.com/shurutech/reboot/blob/main/selfhosted-coding-agent/llm_server.ipynb
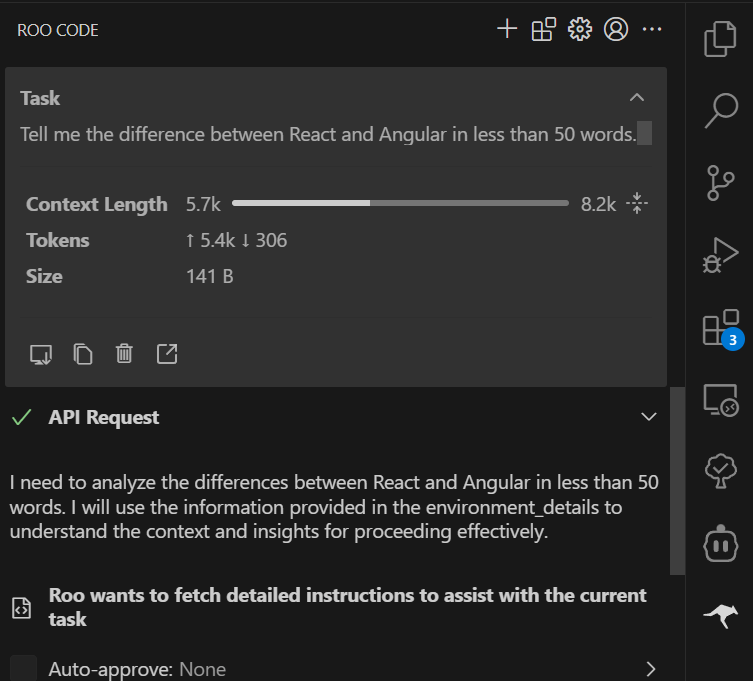
Running via IDE Agents (Roo Code):
- Setup
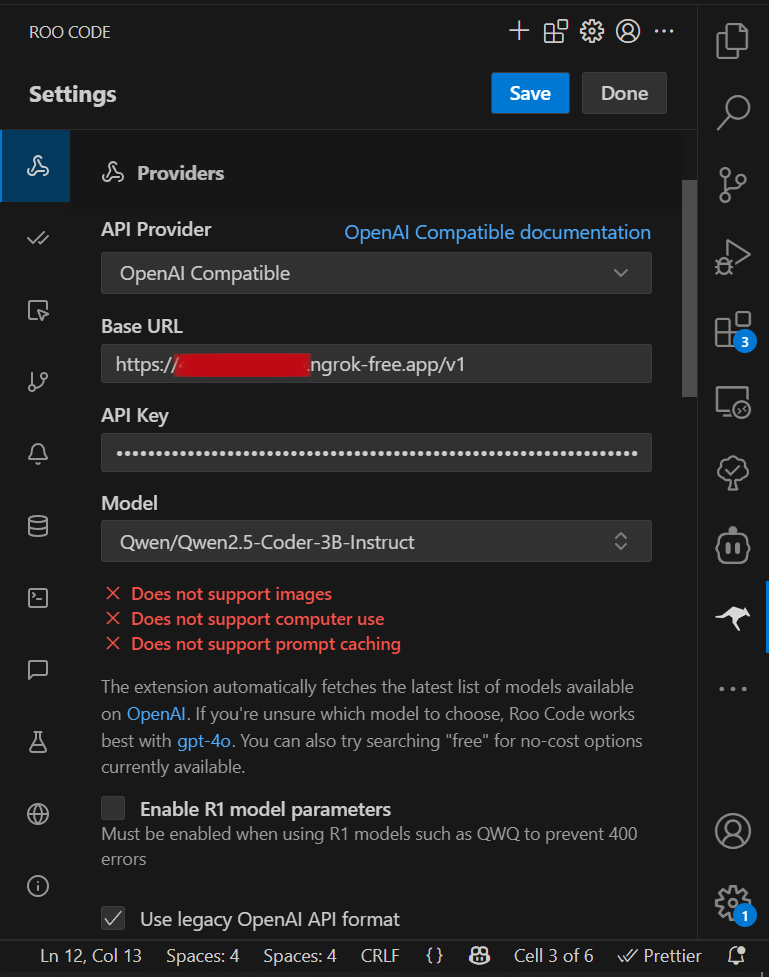
- Demo:
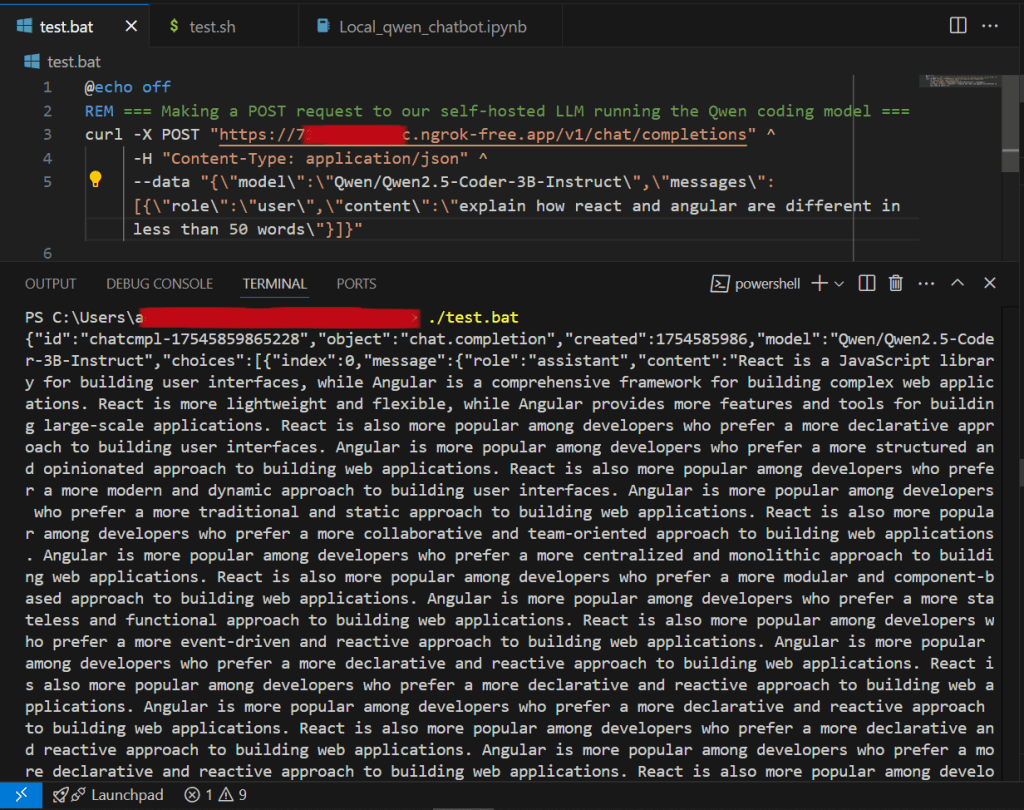
Running via command line (powershell):
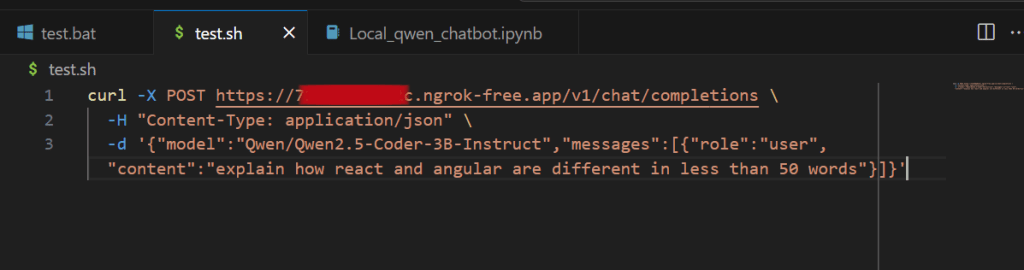
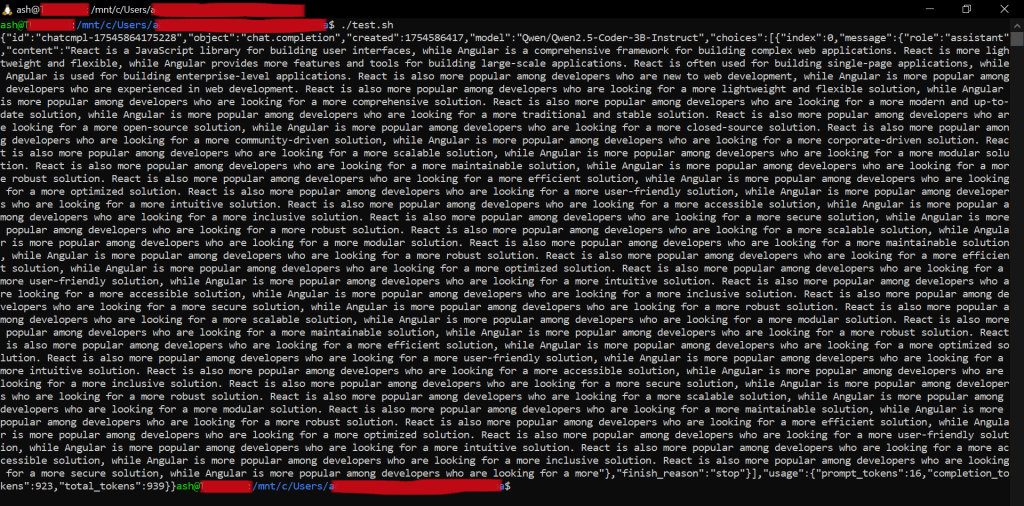
Running via command line (Bash/WSL):
Key Takeaways
- A single‑GPU setup with 16 GB VRAM may realistically host a 3B parameter model in FP16; however, the throughput from consumer GPUs will not match that of Data Center GPUs.
- Marketplace clouds like TensorDock often undercut traditional GaaS players by more than 3× on mid‑range GPUs.
- Token APIs (Groq, OpenRouter) shine in terms of latency, but without the LoRA weights and token-agnostic pricing, they can be counterintuitive in terms of pricing, if model use is very high (For example, Agentic AI).
See: https://shurutech.com/openrouter-experiment-phase-1-power-users-how-our-top-ai-developers-really-work/#model-usage. - By choosing either a more-powerful GPU or by choosing a low-weight (pun unintended) model, one can stick to the good practice of always leaving room for at least a few GBs of VRAM (say 12.5%) margin to safeguard against OOM process autokills. (This is especially relevant if self-hosted locally running AI models are being pursued beyond the enthusiast/amateur scale).
What’s Next?
As with this experiment successfully showcasing the local LLM approach for power coding agents, Shuru Labs will continue to explore the feasibility of “bare metal”-like or self-managed LLM provisioning options. Though a complete pivot in this direction would leave us more reliant on open-weight models (their continued development in the open source AI community), it would also help us navigate the ever-changing field of AI tools, since our AI tooling costs and SLA availability would become more predictable.
We would also have better hands-on data w.r.t individual model usefulness and its infra caveats (as opposed to being locked-in to one provider/model only).
Setup Reference Specs
Model Spec: Qwen 2.5 Coder 3B Instruct
- Parameters: 3.09 billion
- Context length: 32,738 full tokens. 8192 generation tokens.
Hardware Spec:
- CPU: Intel Core i9-12900K, 3.2GHz – 5.2GHz, 16 cores/24 threads.
- RAM: Corsair Vengeance 64 GB DDR5-4800MHz.
- Storage: Samsung 4TB PCIe NVMe.
- GPU: Nvidia RTX 4080 16GB GDDR6X, 716 GB/s bandwidth, ≈97 TFLOPS FP16 tensor compute.
Software Spec:
- OS: Ubuntu 22.04 LTS over Windows 10 via WSL 2.
- CUDA 12 Toolkit and cuDNN 9.
- Anaconda/Miniconda and Python 3.10.
- nVidia GPU driver ≥ version 552.12.
Setup: Detailed setup instructions are available at https://github.com/shurutech/reboot/blob/main/selfhosted-coding-agent/setup_instructions.md
Quantization and 8GB GPUs
For readers on smaller cards (For ex, an RTX 3060 12 GB or 8 GB MacBooks), quantizing to 4‑bit (GGUF/EXL2) cuts memory requirements roughly by half, and lets you load a 13B model in 8 GB with minimal/manageable quality drop. Tools like llama‑cpp‑quantize and bitsandbytes make this a one‑command process – stay tuned with Shuru Labs for our future quantization experiments.
Bonus: A 24 GB graphics card option worth considering
The RTX 4090 24 GB offers nearly double the tensor throughput of an RTX 4080, while costing as low as $0.35 / hour on TensorDock Community hosts – often the best price per TeraFLOP amongst single‑GPU options.
Disclaimer:
Shuru is not affiliated with any third-party GPU-as-a-service/Cloud AI solution providers/Proprietors mentioned in this article. This article neither endorses any single mentioned service over the others (nor does it endorse any mentioned services in general), nor was sponsored by for/paid for by any proprietors mentioned in this article. This experiment and its exploration of feasible solution providers was for educational purposes only. And any commendations/criticisms for any service/entity/provider mentioned, is purely analytical and subjective in nature.