
In today’s digital age, customer service experience plays a vital role in ensuring customer satisfaction and building brand loyalty. However, traditional customer service teams often face challenges in providing prompt and accurate responses due to the overwhelming volume of inquiries. Thankfully, with the advancements in AI technologies, businesses now have the opportunity to revolutionize their customer service experience using innovative solutions like Large Language Models (LLMs).
In this blog post, we will explore integrating GPT (Generative Pre-trained Transformer), which is one of the top Generative AI solutions today, into the customer service experience and how it can transform the way businesses interact with their customers. Specifically, we will focus on chat-based customer service and delve into the potential of GPT as a powerful tool for improving response accuracy and efficiency.
Table of Contents
Role of Customer Service & Ways of Working
Customer service agents form the frontline of communication between businesses and their customers. They handle a wide range of tasks, including addressing inquiries, troubleshooting issues, and providing product information. Understanding the scope of work of customer service experience is crucial for appreciating the benefits of integrating GPT into this domain.
How Customer Service Agents Work?
Traditional support agents typically rely on their knowledge, training, and access to relevant information to assist customers. They respond to customer queries either through phone calls, emails, or live chat systems. While they strive to deliver accurate and timely responses, the volume of inquiries can often lead to delays or inconsistencies in customer service experience.
Source of Truth for Support Team Members
To address customer queries effectively, support agents often rely on a “source of truth”. This could be an internal portal backed by a database or a collection of documents, such as PDFs or manuals, that contain information about the company’s products or services. These sources provide support agents with the necessary knowledge and guidelines to assist customers. These data sources are also the foundation that is used to train new members of the Support Agents team.
So, in effect, the customer queries are often a conversation between the user and this data source, via a human being which is the support agent. The agents do 2 things here –
- They understand what the user is trying to ask, as the queries can be vague and indirect.
- They understand the data from the source and formulate a response that the user can now understand as well.
This is where LLMs come into the picture. LLMs like GPT have proved that they can understand what the users are trying to say in the prompts and if you can give these models the same context (data) as our agents have, then they can manage the user queries as well.
Using the Customer Service team data with GPT
Continuing from the first topic, where we discussed the data source utilized by support agents, let’s explore how you can leverage this data source in conjunction with GPT. By integrating the data source into the GPT system, you can forward our real user queries to GPT and use its responses to interact with the user.
2 Approaches to using GPT
You can build an intermediary system that can process user messages and act as a middle layer between the chat system and the GPT APIs. This system will need to have full access to the data sources, let’s say a Database or a set of manuals or PDFs that the support team uses. Its role is to receive user queries, extract relevant information from the data source, and communicate with the GPT model to generate appropriate responses.
Now, there are 2 ways you can pass on this information from the data source to GPT. You can do this with smart prompts or “prompt engineering”, and the other way is to use the data to fine-tune the GPT models. Let’s look at both to understand how they work.
Prompt engineering
As mentioned earlier, this involves designing specific instructions or prompts for the GPT model. In the context of utilizing the data source, prompt engineering becomes crucial to ensure that the prompts guide the model to utilize the relevant information available in the data source and provide accurate and informative responses. Let’s look at this with an example.
Let’s use the GPT 3.5 turbo model of OpenAI with Chat Completions API. You can find more details here.
In this API, you can pass multiple chat messages to GPT, as a list and tell GPT which messages are sent by which entity. It relies on the “role” parameter to decide the entity type, and the possible values of “role” are system, user, or assistant.
Now, for our example, let us assume that the user is enquiring about a delayed order on an e-commerce website. For GPT to answer users’ queries, it needs to know about the user’s details like name, email, and the order’s details like the status of the order, meaning of different order statuses etc. So an example API request body for such a use case can look like the following
{
"model":"gpt-3.5-turbo",
"messages":[
{
"role":"system",
"content":"Assume that you are a Customer Service Executive of a website called as ecommerce.com and you have to answer about user's queries regarding an order. The order number is XFFGAGG, it is a dish washer. The current status of the order is DELAYED_BY_SELLER, which means that seller is out of stock for this item. Usually it takes less than 10 days for such orders to ship. If the order does not ship in next 10 days, then user's money will be refunded."
},
{
"role":"user",
"content":"Hello!, I had ordered this thing 5 days back, it is saying delayed. It was supposed to be delivered today, where is it ? why not delivered ?"
}
]
}
Code language: JSON / JSON with Comments (json)As this conversation grows, you can keep passing the complete trail of the chat to GPT, tweak prompts in the system role message and let GPT handle the conversation. Please note that this is just an example. Your actual system role messages can be quite large depending upon the use case, and there could be cases that you have the write more precise versions of the context to avoid any token limits from GPT
{
"model":"gpt-3.5-turbo",
"messages":[
{
"role":"system",
"content":"Assume that you are a Customer Service Executive of a website called as ecommerce.com and you have to answer about user's queries regarding an order. The order number is XFFGAGG, it is a dish washer. The current status of the order is DELAYED_BY_SELLER, which means that seller is out of stock for this item. Usually it takes less than 10 days for such orders to ship. If the order does not ship in next 10 days, then user's money will be refunded."
},
{
"role":"user",
"content":"Hello!, I had ordered this thing 5 days back, it is saying delayed. It was supposed to be delivered today, where is it ? why not delivered ?"
},
{
"role":"assisstant",
"content":"Sorry about that, it is delayed by the seller..."
},
{
"role":"user",
"content":"..."
},
{
"role":"assisstant",
"content":"..."
}
]
}
Code language: JSON / JSON with Comments (json)Fine-tuning
Fine Tuning is another approach that involves training the GPT model on specific data and not passing any System-level context like above. However, in the context of utilizing the data for customer service experience, fine-tuning may not be the most suitable method. We will cover the reasons for this, but first, let’s understand how is fine-tuning done with GPT models.
Open AI offers all its models to be fine-tuned. The format for tuning is as shown below.
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
Code language: JSON / JSON with Comments (json)How this works is that it fine-tunes the base model with your prompts and the corresponding completions. As with the base LLM, eventually, it is predicting the most probable (or dare we say, interesting?) next word in a sequence of words (prompts). So when you give your data of prompts and corresponding completions, the outputs of the fine-tuned model are highly tilted towards the data that you provide.
Now, you can assume that this can be easily done with the historical chat conversations data, as any chat system would definitely store all the previous chat conversations and it is golden data because actual real agents have resolved real queries from real users in those past conversations.
So why do we say that this might not be the best solution and why prompt engineering would be better here?
The answer to this is simply because the majority of the past chat conversations would have happened between 2 humans, and thus they are very informal. It is not possible to extract good prompt & completion data from such conversations.
Imagine a normal chat support conversation, or see any conversation where replies are quick. You can look at your WhatsApp conversations as well to get an idea. It might look something like the below –
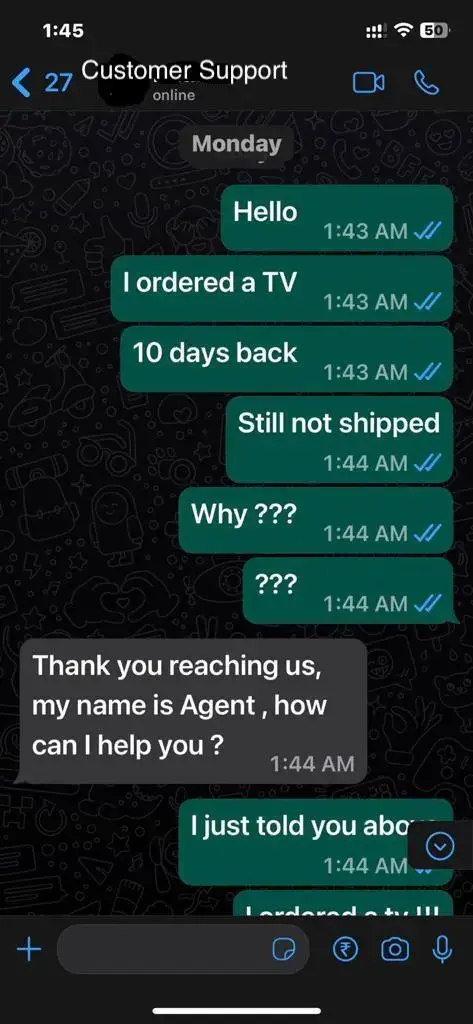
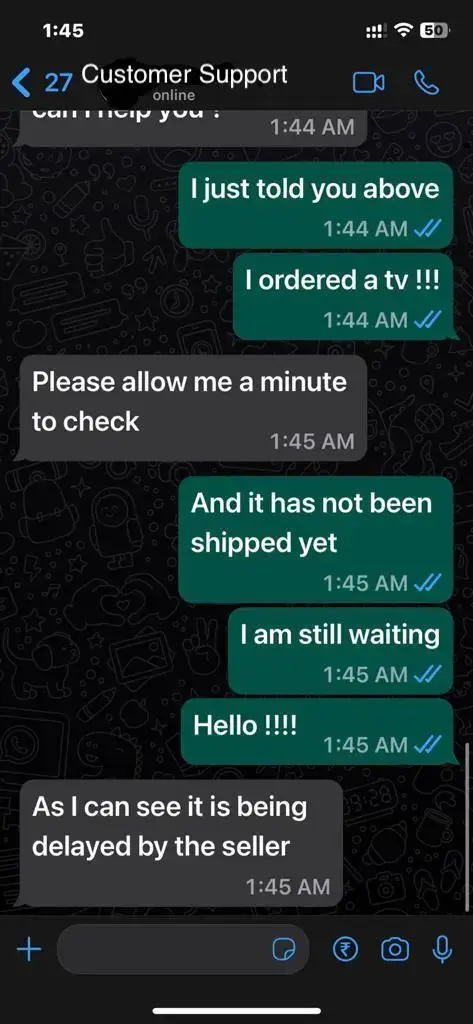
While the agent has not even replied, the user has sent 4 different messages, and while the agent is replying, the user has repeated the messages. So one individual message from the user does not have a single message response from the agent and vice versa. So there is no prompt-completion kind of data available here. For example, what will be the completion of the message ??? from the user?
Maintaining the History & Notion of a Conversation
One important thing to note here is that as such, the GPT APIs don’t have a conversation history or past context. Unlike the web interface, which keeps the context of the current ongoing conversation, the APIs don’t do that. So to be able to pass the complete conversation history in the chat completions API, our intermediary system that we discussed above will have to persist the complete conversation, and then construct the request body with complete conversation data in each following API request. Without this, GPT would lack the overall conversation context and responses would be sub-optimal.
Monitoring the quality of responses
Ensuring the quality of responses generated by GPT-based customer service experience systems is essential for maintaining customer satisfaction. While the primary method of monitoring response quality could involve human evaluation, it can be a resource-intensive process. However, there are some less efficient, good starting point approaches, such as leveraging GPT itself to provide self-assessment ratings. Let’s explore these monitoring techniques in more detail.
Human Evaluation as the Primary Method
Traditionally, monitoring the quality of responses generated by GPT-based systems involves having a dedicated team of human evaluators. These evaluators could review a random sample of conversations and assess the quality of the GPT responses. If any issues or inaccuracies are identified, they can be reported for further improvement and also can be used to switch off the feature and roll back to complete human agent handling of conversations. However, maintaining a human evaluation team can be costly and time-consuming.
Leveraging GPT for Self-Assessment
To mitigate the resource requirements of human evaluation, an alternative approach is to rely on GPT itself for self-assessment. Please do note that this is not ideal and could be a subpar method to monitor your customer service experience.
So, by constructing the response in a way that prompts GPT to rate its confidence and quality, you can gather valuable feedback on the reliability of the generated response.
For example, the response generation process can include a step where GPT rates its response on a scale of 1 to 5 based on its confidence level and the available context. This rating reflects how reliable GPT believes its response is. This can easily be done by prompt engineering.
By tracking the self-assessment ratings provided by GPT, you can gain insights into the quality and confidence levels of the generated responses. The monitoring system can capture and analyze these ratings over time to identify any degradation in response quality. If the ratings consistently fall below a certain threshold, it can indicate a need for intervention and further investigation. As a quick automated action, if the GPT response has a confidence score of 3 or lesser let’s say, our intermediary system can decide to assign the conversation to a human agent and remove the bot from that conversation. This way, customer satisfaction can be prioritised over automated support and the human agent can continue the conversation.
While human evaluation remains the gold standard for assessing response quality, utilizing GPT’s self-assessment ratings offers a more accessible and cost-effective method. It provides valuable feedback that can help identify trends and areas for improvement in the customer service experience system.
Ability to fallback to a Human Agent
In any customer service experience system powered by GPT or similar technologies, it is crucial to have a mechanism in place to fall back on a human agent when needed. While GPT can handle a wide range of queries, there may be instances where its responses are not satisfactory or require human intervention. LLM hallucinations are a big concern and they can happen in any conversation. Let’s explore the importance of this fallback mechanism and how it can be implemented effectively.
Ensuring Quality and Customer Satisfaction
The primary goal of any customer service experience system is to provide high-quality assistance and ensure customer satisfaction. While GPT can offer accurate and helpful responses in many cases, there may be situations where its understanding or context interpretation falls short. By allowing a fallback to a human agent, the system can ensure that complex or critical queries are handled by experienced professionals, guaranteeing the best possible assistance.
Implementing a fallback mechanism can be considered a dynamic feature flag within the customer service experience system. The intermediary system acts as a gatekeeper and evaluates the quality or relevance of GPT’s responses. If the system determines that the GPT response is not up to the mark or requires human judgment, it can dynamically assign the conversation to a human agent for further assistance.
What are the Limitations & Gotchas of GPT?
GPT is a powerful language model that can be used for a variety of tasks, including customer service. However, there are some limitations and gotchas to be aware of when using GPT for this purpose.
One limitation of GPT is that it is not able to handle complex or technical queries. GPT is trained on a massive dataset of text and code, but it does not have the same level of understanding as a human expert. As a result, GPT may not be able to provide accurate or helpful responses to complex or technical queries, basically, anything that is out of the context of the prompt.
Finally, GPT would not be able to talk to external parties or talk to people to figure out the response to a user’s query. GPT is a language model, not a human being. As a result, GPT cannot interact with the real world in the same way that a human can. This means that GPT cannot access information that is not publicly available, and it cannot resolve issues that require human intervention.
Here are some examples of scenarios where GPT would not be able to handle a user’s query:
- A user asks a query that might need the agent to talk to a third party, like the seller on an e-commerce website.
- A user asks a query that is outside the scope of the database of the support team and thus the support agent has to talk to their higher-ups or peers for the same.
Conclusion
In conclusion, the application of GPT for customer service experience has the potential to revolutionize the way businesses interact with their customers. Its ability to understand and respond to a wide range of inquiries is truly remarkable. However, it is crucial to exercise caution and maintain constant monitoring when deploying such technology. While GPT can enhance efficiency and improve customer experiences, it is essential to address potential risks such as biased or inappropriate responses. By implementing robust monitoring systems, ensuring ongoing human oversight, and regularly updating the model, you can harness the power of GPT while upholding ethical standards and delivering exceptional customer service experience.