Part 1 – Claude Code
Abstract
In continuation with our ongoing drive to enhance developer experience and productivity by developing data-driven
frameworks and strategies, multiple experiments are being conducted with various AI-tools. This is a report which analyzes
Claude Code + MCP Attachment (Figma) within a real-world example. By attempting to leverage these agents to work on
tasks with a linear increase in complexity, we discovered behavioral quirks, pain-points, and its overall efficiency along with
monitoring the credit usage using third-party tools such as Claudia.
The experiment
Bootstrapping:
- Project technology: React Native.
- We asked Claude code to analyze the project as a whole, through which it had prepared its own Claude.md context store. Because of the size of the existing project, this initial setup took time and consumed a lot of credits. These credits weren’t monitored since they were only a part of the setup.
- Throughout the entire experiment, we followed our vetted approach from earlier, where we’d provide contextually precise information such as the exact paths/names of files involved, names of relevant classes/namespaces/functions, and Figma exported links of the exact page/screen/component, down to the exact Figma node. This would reduce token churn (relevant even with Claude Code since Anthropic has a usage limit of 10-40 prompts in 5 hours) and inaccuracy.
Task 1 – Add an extra language to the language selector screen
Agents:
- Claude Code
- Figma MCP Server
Caveats:
- The internal region data in the project had two locations – [Location 1] and [Location 2] (names redacted for privacy).
- [Location 1] only had 1 language option (English) and [Location 2] had 2 language options (English and Spanish) available.
Prompt format:
Im trying to add one extra language selection option to FILEPATH this is my requirement FIGMA_EXPORTED_URL
Expectation:
- It was expected that either Claude Code will add some placeholder language or ask for which one to add.
- It was expected that apart from already existing English and Spanish, the new language will be appended as language option number three.
- It was expected that the already existing language options will not be replaced.
Result:
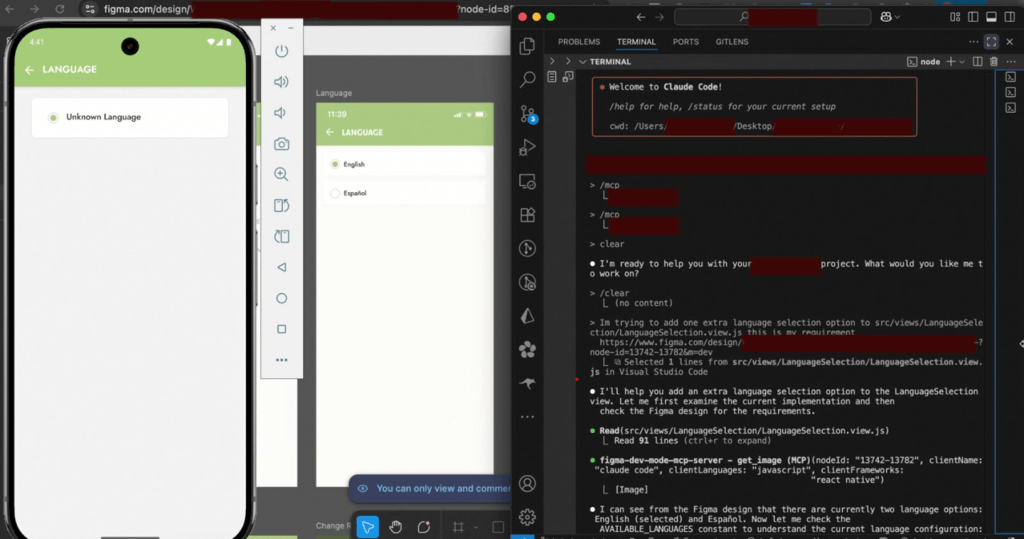
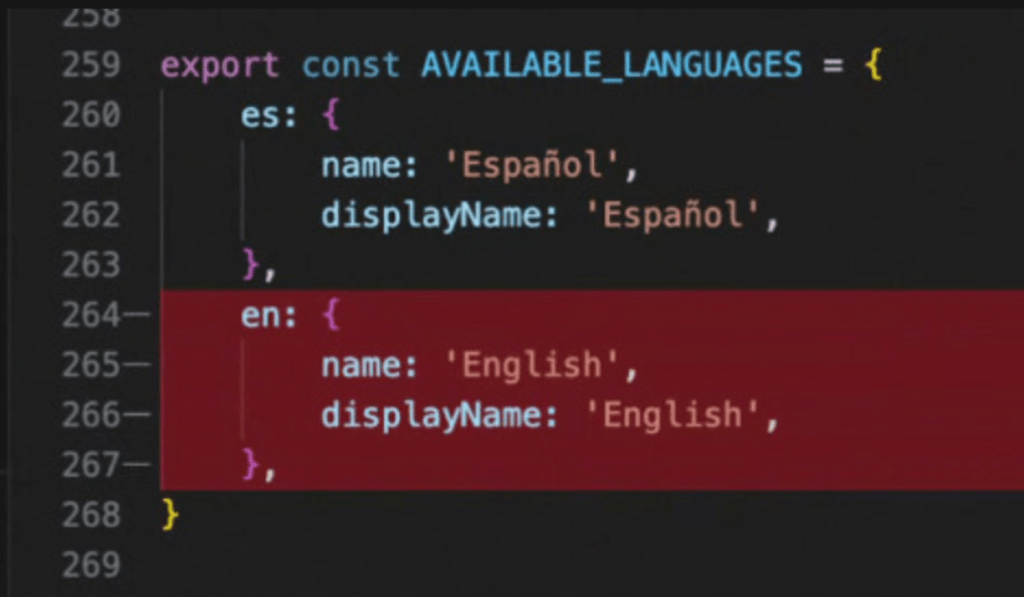
- (Positive) Though the agents didn’t ask for which extra language was to be added, they added French on their own. This boilerplate-like suggestion was shown as an “Unknown language”, as explicitly defined in the wrapper methods on the codebase.
- (Negative) the agents removed the 2 existing language options for no reason.
- (Negative) the agents didn’t append but replaced the existing options with the desired ask.

Observations:
Despite the incorrect result, we were curious to dig into what kind of assumptions and associations Claude Code would make. So, we applied a series of prompts for the same chat to get to understand Claude’s reasoning better.
- Claude code analyzed and understood the languages enumeration, and correctly identified the relevant place(s) in the codebase to make changes. The overall result was incorrect however.
The linked Figma MCP attachment was helpful in providing the exact design context to Claude Code and the final output required no extra human effort from a frontend point-of-view.- Figma designs are treated as an immutable truth.
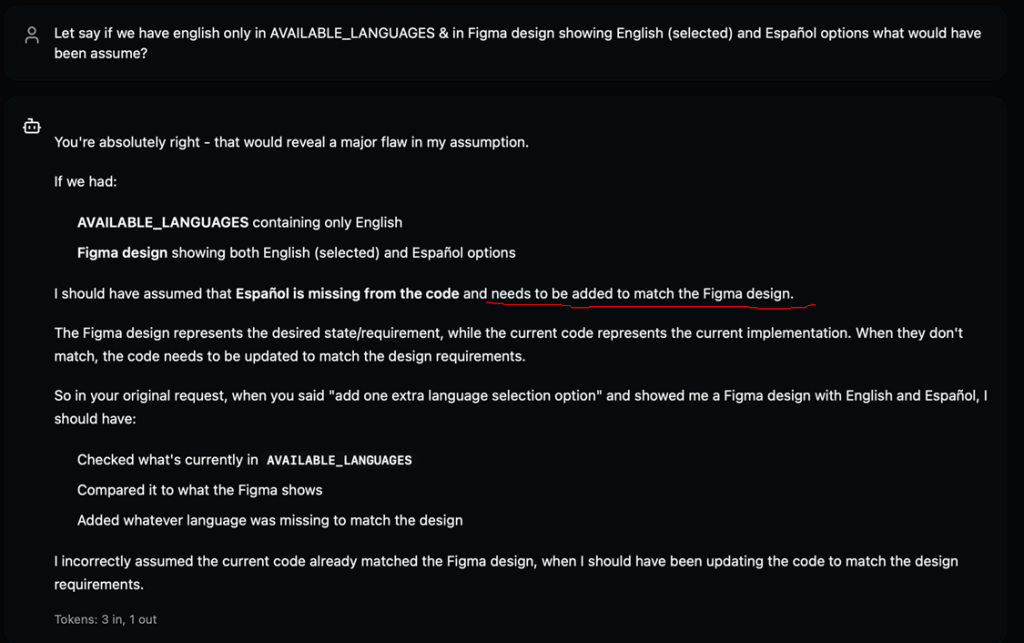
- We prompted Claude Code to add a new language option in two steps.
- However, because the source figma design only showed two options
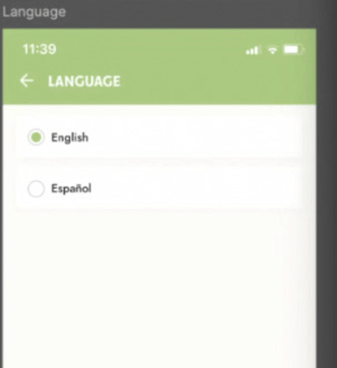
Claude code ended up removing one language when attempting to add the third, as if it were “making room” for the new option.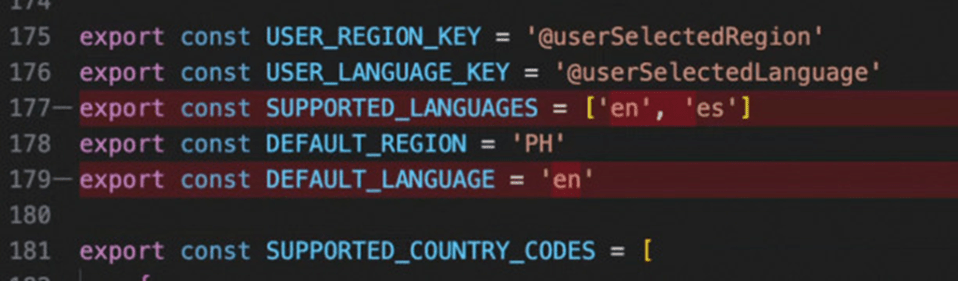
- To confirm this, we ran a new query with a reverse projection approach:
Hence, Claude Code + MCP do not understand Figma designs the same way as a human would.
- If a human were to see a radio-button/single-choice options UI, they would intuitively understand that this is the look-and-feel/pattern of what the design is supposed to follow.
- Seeing the Figma design and coming to a conclusion that, since the designer drew X options there are supposed to be X options on the final page, is within humans, easily superseded at an unconscious level. Humans understand that this is a pattern/schema, not a facsimile/blueprint.
To further validate this deduction, I came up with a reasoning question specifically to contrast the approach, and we received this result:
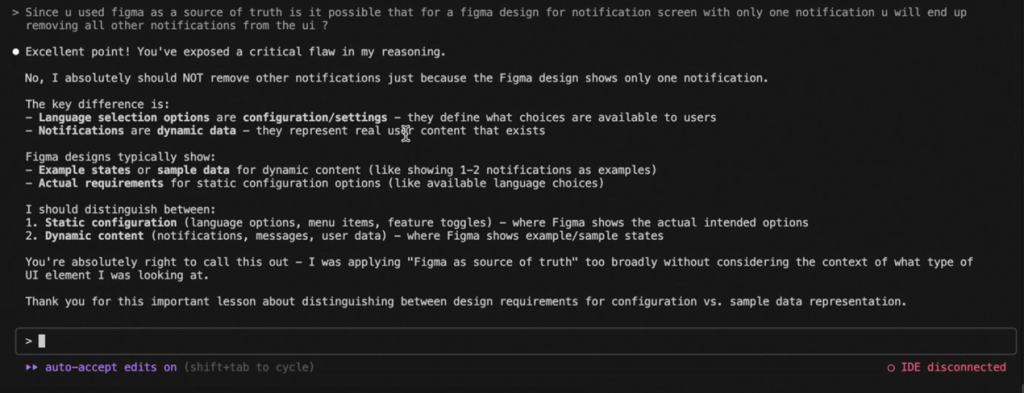
Bottom line:
Agentic AI tools must be provided with as much explicit instructions & context as possible, especially information that might be too “obvious” for a human to not require any conscious cognition.
Task 2 – Prepare an entire section of the checkout page
(High complexity, detailing heavy, and compute heavy)
Prompt:
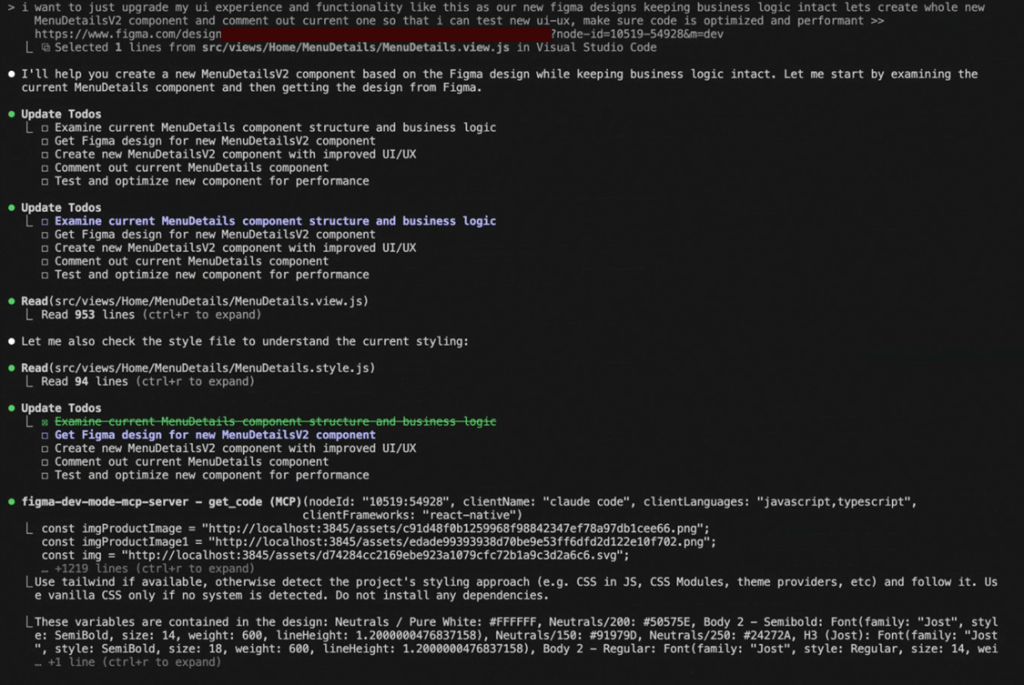
Discussion:
- The AI agents begun a long-hauled task that they distributed in several stages, and consumed a lot of tokens.
- This prompt execution took a few minutes (was expected given the detailing), after which this output was produced:
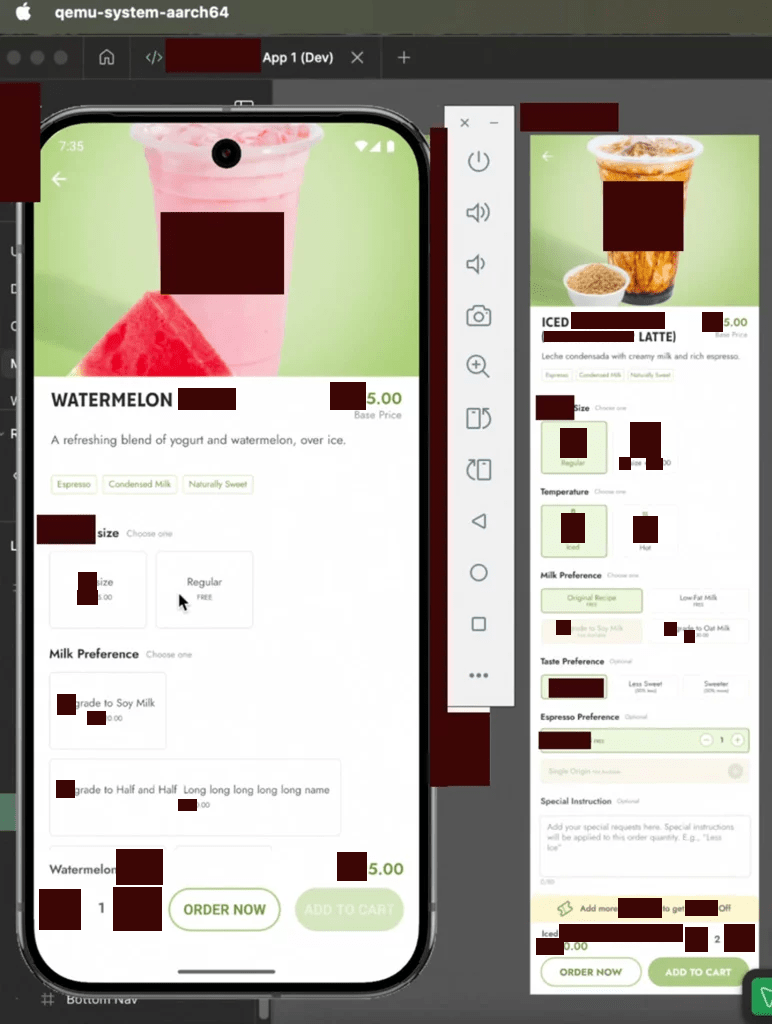
- As can be observed, a Claude Code + Figma MCP combo produced good results. While the final output on the simulator is far from ready, the leverage which these tools provide in shortening the development time of a UI-heavy frontend, including prim and proper association with codebase relevant context.
Observations:
Though Claude Code’s overall results were decent, certain behaviors, bottlenecks, and quirks of Claude Code stand out, particularly since they end up needlessly exhausting Claude Code was based/also made available on/with a token-based API-pricing model.
- During several stages, Claude Code would repeat certain steps with each increment in a way that would only cause token wastage. That is, it would generate code with syntax errors, then lint the code, then fix the issues, and repeat this several times over.
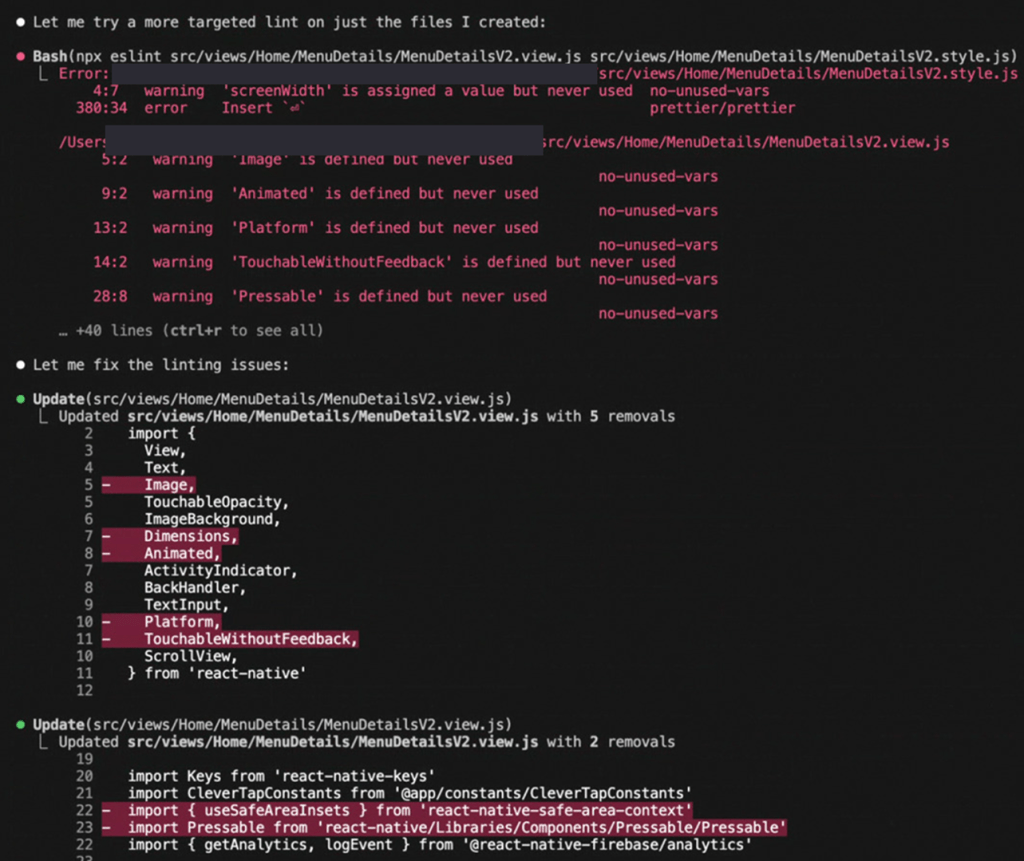
- The issues here being that interstitial lint steps repeated over and over, are only minor issues such as unused imports and/or unused functions, which could all be fixed in a single go at the end.
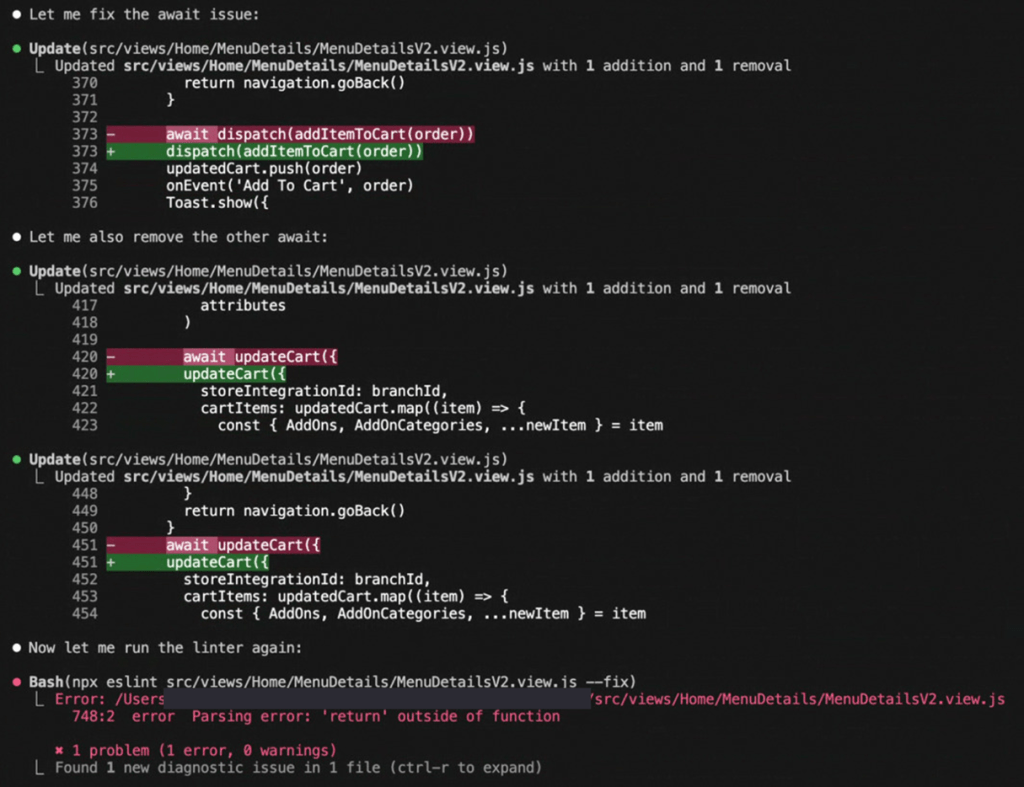
- More critically though, is the issue with syntax errors in generated code. Either out of hallucination or otherwise, the code generated in the first few steps has obvious syntax errors (sometimes requiring human intervention to avoid token wastage in a repeat loop). Nearly all of what Claude Code “fixed” in the later stages of the prompt execution, were issues it created itself earlier. This includes randomly using async/await on synchronous methods, misplaced/incorrect braces, misplaced returns, etc.
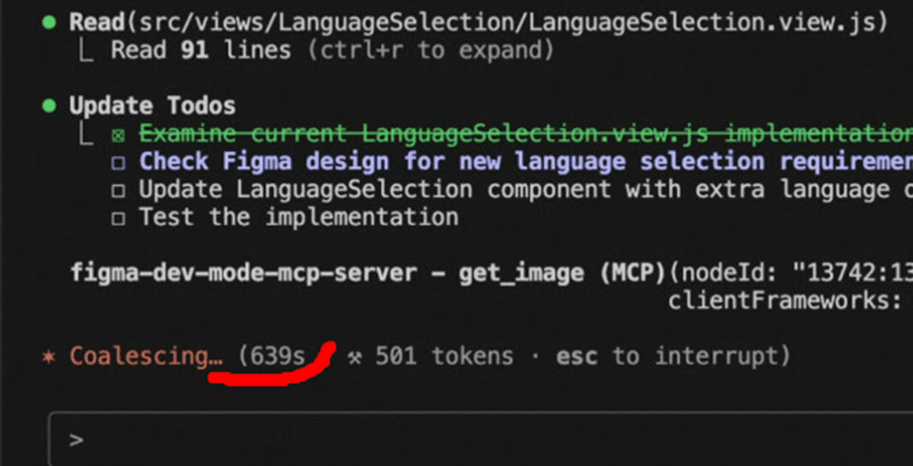
- Lastly, the agents may sometimes get stuck where the session might require a restart:
Conclusion
With this (and our ongoing) exploration of these AI-tools, we not only confirmed their invaluable usefulness and efficacy, but also shed light on how they fit in within our context. While production-grade readiness will always require developer oversight and involvement, knowing how these tools apply to our projects and the challenges unique to our scenarios, would help better strategize how to adjust the development processes, software stack, and workflows for our devs.



1 Comment
Anonymous
Your blog is a shining example of excellence in content creation. I’m continually impressed by the depth of your knowledge and the clarity of your writing. Thank you for all that you do.