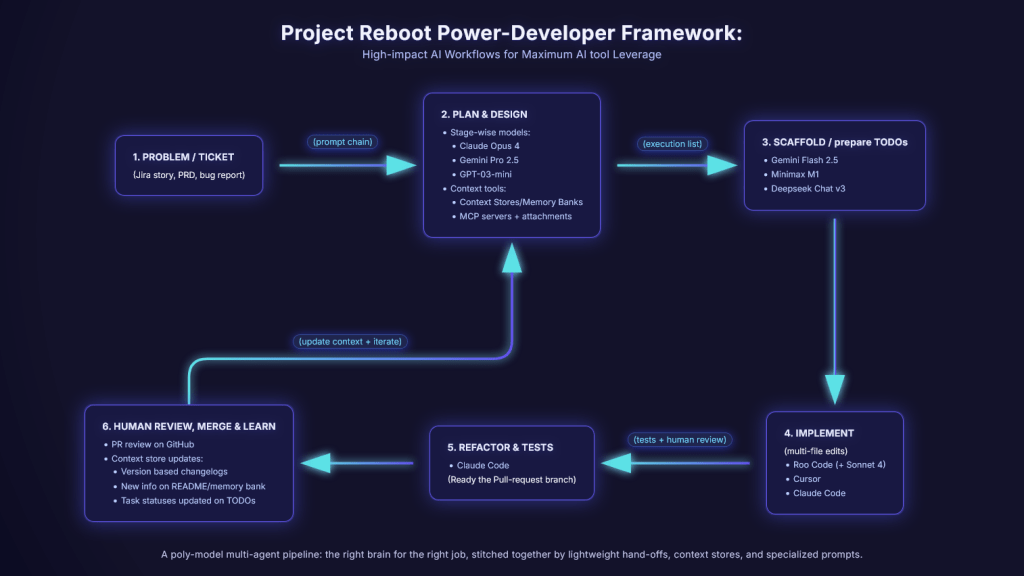
Fig 1. The framework we propose through this report.
(A poly-model multi-agent pipeline: the right brain for the right job,
stitched together by lightweight hand-offs, context stores, and specialized prompts.)
1. Background
Continuing with Project Reboot’s drive to standardize and maximize AI-powered development, we conducted a credit-swap experiment. All developers at Shuru currently enjoy both ChatGPT team and GitHub CoPilot subscriptions. For developers in the OpenRouter Experiment (ORE) participant pool, we allocated USD 19 in OpenRouter API credits (the exact monthly cost of Copilot), as the primary tool for the study, while retaining their existing Copilot access to ensure uninterrupted client delivery. This setup enabled us to obtain an apples-to-apples comparison and a cost-benefit analysis of transparent agent/model agnostic workflows versus a closed-loop agent subscription, as well as to conduct rich studies and parallel experiments through extensive and meticulous collection of developer behavior and AI-tool usage data.
Among a pool of 12 participants, four engineers (the ORE Band 1 cohort) burned through their entire credit allowance in less than 12 calendar days. This post digs into:
- Who we call a “power user”.
- A subset of the methods and metrics we have collected and collated so far.
- The apparent associations and patterns that we are studying between high AI tool usage cohorts on the OpenRouter Experiment (ORE bands) versus how they relate with the self-reported AI-generated code percentage metric (Code generation percentage CGP bands) extracted from the internal survey.
- Detailed case‑studies of real prompts, including successes and failures.
- Early patterns that predict high leverage.
- Concrete next steps and tooling gaps that the industry still needs to close.
For background, read Blog 1 (Project Reboot – A New Default) and Blog 2 (Mapping the AI Terrain – Cohort Analysis).
2. Experiment Setup in a nutshell
2.1. Parameters
| Parameter | Setup |
| Participants | 12 engineers (mobile, backend, infra) |
| Replacement | • Before: Monthly GitHub Copilot Access • After: USD 19 in OpenRouter credits (price‑matched) |
| Timeline | • 30‑day experiment • Rolling non-invasive interviews, as soon as a participant exhausts their credit |
| Data collected in this subset | • Credit logs • Agents and models information • IDE telemetry (beta) • in‑depth 1‑on‑1 interviews |
| Data collated for this subset | • Cohorts from the internal survey • Usage bands within this experiment • Toolkit usage patterns and their association with technology cohorts, domain cohorts, and previously surveyed Code Generation Percentage (CGP) cohorts. |
2.2. Classifications
| Band/Group | Definition | Standardized Cohort ID |
| ORE Band 1 | OpenRouter experiment participants who • Have used ≈$19 (100%) of credits. • Do not have any usable credits left. At the time of the analysis cutoff. | COHORT/ORE/BAND_1 |
| ORE Band 2 | OpenRouter experiment participants who • Have used between $14.25 (75%) to $19.00 of credits. • Have usable credits left. | COHORT/ORE/BAND_2 |
| ORE Band 3 | OpenRouter experiment participants who • Have used between $09.50 (50%) to $14.25 of credits. • Have usable credits left. | COHORT/ORE/BAND_3 |
| ORE Band 4 | OpenRouter experiment participants who • Have used between $04.75 (25%) to $09.50 of credits. • Have usable credits left. | COHORT/ORE/BAND_4 |
| ORE Band 5 | OpenRouter experiment participants who • Have at least used between $0 (non-zero percentage) to $04.75 of credits. • Have usable credits left. | COHORT/ORE/BAND_5 |
| ORE Band 6 | OpenRouter experiment participants who • Have been inactive/have not used any credits. • Have the full $19 of limit left. | COHORT/ORE/BAND_6 |
| CGP Band 0 | Engineers who self-reported, to have less than 25% of AI-generated code, in their final output. | COHORT/CGP/BAND_0_25 OR COHORT/PERC/BAND_0_25 |
| CGP Band 25 | Engineers who self-reported, to have between 25-50% of AI-generated code, in their final output. | COHORT/CGP/BAND_25_50 OR COHORT/PERC/BAND_25_50 |
| CGP Band 50 | Engineers who self-reported, to have between 50-75% of AI-generated code, in their final output. | COHORT/CGP/BAND_50_75 OR COHORT/PERC/BAND_50_75 |
| CGP Band 75 | Engineers who self-reported, to have more than 75% of AI-generated code, in their final output. | COHORT/CGP/BAND_75_100 OR COHORT/PERC/BAND_75_100 |
3. How We Gathered the Data
- Credit Telemetry – API cost + model usage logs.
- Cohort Labels – Via both self‑reported Code‑Generation‑Percentage (CG %) from the internal survey, and via OpenRouter credit usage logs.
- Semi‑structured Interviews – 90-120 minutes each; prompt walkthroughs recorded.
- Artifact Mining – Observed and questioned the intent behind usage of README files,
.mdcCursor-IDE files, IDE chat histories (opt‑in), and other memory assets or ‘banks’ utilized by power users.
(Full methodology appendix lives in an internal PDF and will be open‑sourced after review).
4. Who are the Power Users?
4.1. Synopsis
| Anonymized ID | Role and Domain | CGP Band | Agents used within OpenRouter experiment | Agents used outside of OpenRouter experiment | Notable Models Used (Both via OpenRouter and via untracked model usage outside of OpenRouter, but during the course of the experiment) |
|---|---|---|---|---|---|
| Dev A | IC Mobile dev | 75 - 100 % | • Roo Code • Cline | • Claude Code • Claude Pro Individual (Chatbot Web-UI) | Via OpenRouter: • Claude Opus 4 • Claude Sonnet 4 • Gemini 2.5 Pro Via ChatGPT web UI*: • GPT-4.1 |
| Dev B | IC Mobile dev | 25 - 50 % | Roo Code | Github CoPilot Chat (Free tier) | Via OpenRouter: • Claude Sonnet 4 • GPT o3-mini (occasional) Via ChatGPT web UI*: • GPT-4o |
| Dev C | IC Senior Backend dev | 25 - 50 % | • Cursor • Roo Code | • Claude Code • Supermaven | Via OpenRouter: • Claude Sonnet 4 • Gemini Flash 2.5 • DeepSeek Chat v3 • Minimax M1 • GPT-o1 mini (once) • Qwen 2.5 coder (once) Via ChatGPT web UI*: • GPT-4.1 |
| Dev D | IC Backend dev | (unknown) | Cline | • Claude Code • Claude Pro Individual (Chatbot Web-UI) | Via OpenRouter: • Claude Sonnet 4 • Claude Sonnet 3.7 Via ChatGPT web UI*: • GPT-4o |
(Project names and personally identifiable information were removed for privacy).
(*Since ChatGPT team access was neither revoked nor tracked as part of the OpenRouter experiment, the relative comparison between developer reliance on ChatGPT team subscription versus OpenRouter usage through IDE-extensions other BYOK agents, was done on the basis of 1-on-1 interviews and developer responses in the internal survey).
4.2. Profiles
For the table below
- ‘ToolSet 1’/
internal_toolsetrefers to the GitHub CoPilot replacement AI agents & models, that could be and were tracked during this internal OpenRouter experiment. - ‘ToolSet 2’/
external_toolsetrefers to the (unrelated) Chatbot/Web-UI access to GPT models, via the ChatGPT Team subscription that is available to every developer org-wide, but is external to this experiment and could not be tracked.
| Anonymized ID | Proficiency and Style | Subjective experiences through the OpenRouter experiment |
|---|---|---|
| Dev A | Very High. He is parallelly, also a part of a different ongoing AI-experiment. 1. During the OpenRouter experiment, used a multi-step development workflow that leverages both reasoning and general-purpose models (Opus 4 and Sonnet 4), an MCP server + Figma attachment, and a manual single-agent multi-model handover between the intermediate results, with manual oversight and review in between the steps. 2. The reasoning models (Opus 4) were used to write instructions, which were then fed to general-purpose LLMs (Sonnet 4) via automatic mode in IDE-extension AI-agents (Roo Code) to produce the overall code. 3. An MCP server alongside its Figma attachment, was used occasionally when needed, to provide context to the models during the planning phase. Further, specialized configurations and agentic prompts sourced via public repositories were also used depending on the use case. 4. During the course of the experiment, he made near-exclusive use of internal_toolset for all phases of dev work – brainstorming, planning, architecture design, implementation steps, and coding. Usage of external_toolset was limited to sometimes cross-verifying/validating output from Claude models.5. Made use of well written and detailed TODOs and markdown files which preserved and logged some context history in a particular manner. These would be worked upon by reasoning models (Opus 4) to create the set of steps and actions that general-purpose models (Sonnet 4) need to follow, to achieve the intended goal. Agentic prompts may also get occasionally used. With a manual review of these model-to-model instruction transfer file in between the handoff, both the model sets (though costlier than average models), are well utilized, with the resultant output hardly requiring much modifications. 6. There are a few instances of tracked/untracked overlap in the usage of GPT models, as GPT models were initially used both through the internal_toolset and external_toolset.7. Later, his usage of experiment-tracked models ( internal_toolset) shifted completely towards Claude 4 (Sonnet and Opus).And usage of GPT-4.1 remained on the untracked side ( external_toolset). | 1. The developer was very satisfied with the experiment as it enabled him to pick-and-choose between multiple models through BYOK compatible agents. 2. However, contradictorily, he has requested access to Claude (not Claude API), which isn’t compatible with the internal_toolset/OpenRouter approach. This is because Claude models (particularly generation 4) and agents (Claude code) have heavily improved his productivity and efficiency to the point where he doesn’t need other tools.3. Still, his stance on GPT models isn’t neutral – even though the external_toolset is not within the purview of this experiment and its access will not be affected regardless, he has vouched in for its usefulness and requested for this toolset to not be discontinued. |
| Dev B | High. 1. During the OpenRouter experiment, made use of external_toolset for brainstorming and internal_toolset for coding, feature-development, and bug-fixing. For some features, GPT-o3-mini was used to generate PRDs which were then fed into Sonnet 4.2. In order to save credits, his prompts are carefully written with pinpointed information such as which bug/issue is arising, on which function/component, which is present inside which filename – using this, combined with his approach to only supply the information most likely relevant, he is able to achieve high token cost utilization with some known issues. | 1. The developer found the internal_toolset and the OpenRouter experiment to be helpful.2. A particular positive experience, was that with the prompting style that this dev follows, with very specific instructions including filenames/paths, the names of functions/namespaces to modify, and the issue/feature at hand, Roo Code + Sonnet 4 were able to make precise modifications to several files with the least number of lines modified – this behavior allowed Git like visual tracking of lines added/removed/modified. Further, React’s exact standard were followed w.r.t the placement of newly generated code (as opposed to adding them randomly anywhere). And by checking code quality with each augmentation, AI-tools reduced review time, made code more modular, and improved code quality. 3. He found that with Roo Code in particular, tasks of low and medium complexity could well be solved. However more complex tasks fail as the agent has context resets due to memory saturation, and hallucinations. 4. Sometimes, the solutions suggested by AI-tools, despite them being incorrect, were found to be interesting – because of the approach that the AI model thought about to solve the issue. 5. However, the pain-points such as context loss (due to context window exhaustion and/or agent auto-reset on model fallback), prompt fatigue, and token exhaustion due to additional token overhead (because of the extra prompt verbosity internally introduced by the agent-layer wrapper) were notable hindrances. 6. Having recently observed the speed and depth-of-assistance that Claude models had provided to his peer pair-programmer, he has also requested Claude Code access. 7. Nonetheless, this developer also maintains a positive opinion of external_toolset. |
| Dev C | Very High. He is parallelly, also a part of a different ongoing AI-experiment. 1. During the OpenRouter experiment, he made use of a contextualized single-agent, multi-model, multi-stage development workflow that utilized an exported-memory based handover. 2. High-cost heavy research models (Gemini Pro 2.5) were used to brainstorm tasks and work on architecture. Low-cost lighter models (Gemini 2.5 Flash) and/or models that have large context windows (Minimax M1), were used to develop context stores or memory banks. Thereafter, general-purpose LLMs (Sonnet 4/Sonnet 3.7) were used to write code based on the context seeded via the agent’s context memory (Cursor .mdc files) banks that were created with previous prompts. 3. He also makes use of profile-specific rulesets and other agentic features such as modes and optimizations as part of his multi-model workflow. | 1. The developer found the internal_toolset and the OpenRouter experiment to be helpful.2. In his experience, he found that AI-tools struggle more with JavaScript (not TypeScript) even with explicit examples, instructions, and pseudocode, than other languages. 3. Though he uses reasoning and research models in the beginning, for most use cases, he finds general-purpose models such as Sonnet 3.7 to be more than enough. 4. With Roo Code, he found that his approach of switching between heavier models (Gemini 2.5 Pro) for research phase, lighter models (Gemini 2.5 Flash) for the planning phase, and general models (Sonnet 3.7 or Sonnet 4), has the shortcoming of requiring model specific rules – to keep it consistent with the workflow, switching models isn’t as simple as choosing different models on a dropdown. 5. With Sonnet 4 (via Roo Code), he found that asking the model to refactor old test cases worked great, as hundreds of (already working but slow) test cases on the entire test case suite were refactored within a few prompts. 6. He also noticed better efficacy with Claude Code versus Claude Sonnet 4/Roo Code. Specifically, for a particular task, both Claude Web-UI and Roo Code gave random suggestions which didn’t work. However, Claude Code got it done within a single prompt. This behavior is apparently consistent, as the same was observed with multiple tasks. 7. Compared to GitHub CoPilot, the absence of a sound tab autocomplete feature was mentioned as a hindrance – he had ended up exhausting his credits since the AI-agents (Roo Code/Cline) used to send full-length prompts to Gemini models, in-between each successive tab keystroke. 8. This made him switch to Cursor to circumvent not having any usable AI-tool credits, however, Cursor’s internal context compression on both input and output wasn’t very helpful either. 9. He has also requested access to Claude Code, and when asked about whether he has a positive/neutral/negative stance on external_toolset – where a positive stance would mean he would want continue access to external_toolset (ChatGPT web), neutral would mean that he’s indifferent, and negative would mean that he doesn’t want access to ChatGPT web – he mentioned that he holds a neutral stance. |
| Dev D | Sub-optimal/Lacking (Self-reported) 1. During the OpenRouter experiment, she followed an iterative process of working on a rough manual solution, then using AI-tools to enhance the working copy. 2. She feels like her prompt/conversation style needs improvement, since other devs have been able to achieve their intended results with AI-tools much faster than her, but (based on her own assessment) she isn’t quite there yet. 3. Her usage of external_toolset is minimal – only used sometimes for learning. | 1. In her case, the replacement of GitHub CoPilot with OpenRouter, showcased some known issues and new challenges (as well as seconded existing ones) that lead to token exhaustion from agent quirk/faulty LLM behavior. 2. In one particular instance, when using Sonnet 4 via CLine, she prompted the model to write test cases. However, despite providing explicit examples stating what to mock and what not to, the model seemed to ignore those instructions and the generated test cases weren’t what was expected. This situation then ended up in downward spiral where a lot of tokens were lost and ultimately re-prompting for test cases to be generated had to be aborted. 3. She finds that Sonnet 4 in particular has a tendency to overcomplicate low complexity items. It works well with tasks such as creating basic CRUD APIs, but for complex items, the solutions created are too complicated, non-optimal (too many DB calls), require careful manual review, and thus cannot be relied upon. 4. When she used a personal Claude Code subscription, she was working on a task where a failed CRON job should trigger sending an email so that all devs/support SRE is aware about the issue. From the codebase, Claude Code quickly figured out that they already have an email provider, as well as the format that they were using, without any instruction/info/prompt about those items, and the code was generated really quick. The overall task was finished within 5 minutes. 5. She has also requested access to Claude Code, and holds a neutral stance on external_toolset, with her usage of ChatGPT limited to ideation and broad architecture questions. |
5. Why it’s working for them
5.1. Iterative Prompting – “Refine, Clarify, Repeat”
A single prompt is never the end. All four users maintain a feedback loop, often 3‑to‑5 micro‑prompts per feature slice.
Case Study 1 – Microservice Bootstrap
A backend dev [1] asked CLine/Sonnet 4 to “Set up a Node JS + TS micro‑service with ESLint, Jest, VTest, Prettier.” The first attempt cost $3-4 USD and generated an unusable monolith. By splitting the request into 7 smaller prompts (one per file) and persisting context in asetup.mdmemory bank, total extra cost dropped to <$1 while achieving a clean scaffold.[1] Developer profile Dev C
5.2. Model/Agent Switching – The New Workflow Primitive
Power users treat models like micro‑services:
| Task | Preferred Model | Rationale |
|---|---|---|
| Architecture sketch | Claude Opus 4 | Best long‑form reasoning |
| Research | Gemini 2.5 Pro | Deep research |
| 1. Creating scaffolds for successive AI-tools in the workflow. 2. Basic note taking, smaller tasks, asking questions. | Gemini 2.5 Flash | 1. Low-cost light model for generation of context-based artifacts, profile-specific rulesets, and prompt enhancement/rewrites for successive models. 2. Cheap, good enough for model-to-model prompt chaining. |
| 1. Writing Code. 2. Implementation of steps given by heavier research/reasoning models. 3. Execution of prompts written via lighter models. | Claude Sonnet 4 via Roo Code/Cline, and (internally) via Claude Code | Power and accuracy, Lower latency, Strong code awareness (for some agents) |
| IDE chat | Roo Code / Cursor | Agent mode inline edits, tab‑autocomplete |
Rather than a one‑size‑fits‑all Copilot, they compose multiple agents — sometimes within the same editor session.
Make it bigger and bolder: Think of this as poly‑model pair programming. Choosing the right brain for the right job cuts latency and spend.
5.3. Memory and Context Craftsmanship
Context‑as‑a-state is real. Two power users actively update some variation of curated context repositories (TODOs and other markdown files, “memory banks”, model-to-model prompt export-files based handovers) reloading them after context resets, and even asking AI agent to rehydrate/rewrite its own memory for consistency.
5.4. Human‑in‑the‑Loop: Still a Copilot, Not an Autopilot™
No code hits main without human review. Power users may blindly trust high‑level plans in side projects, but never production code.
5.5. Context-specific leverage: MCP Servers and Agentic Prompts
- By using extraneous tools such as MCP servers, their attachments (Figma etc.), well-tailored AI agent configurations, and standardized high-leverage prompts, frontend power users can provide the underlying LLMs, with more sophisticated context during the bootstrap/planning phases.
- Beyond setting up subtle context for the LLMs (such as theming information, componentization, and visual palette), this would also reduce the total number of execution cycles (for both the devs and their AI copilot) within which the drafts are refined into their finished products.
5.6. Bonus: The hidden advantage of first-party agents
While all power users asked for Claude Code access largely to capitalize on a prompt-agnostic and token-agnostic usage allowance, even though they weren’t aware about it, their interviews provided a valuable clue during the compilation analysis and consequent preparation of this report:
- Even though internally powered by the same model (Sonnet 4), Claude Code excels in situations where Roo Code doesn’t, because it is a first-party agent.
- Since Claude Code is tied to Claude Pro subscriptions and has time-based but not token based pricing (like Claude API), it is effectively a direct GitHub CoPilot equivalent.
- And the Agent (Claude Code), unhindered by token exhaustion concerns, internally leverages much higher and more detailed prompt overlays and overheads attached alongside user-prompts to Sonnet 4, thus offering superior context awareness, and externally appearing to solve problems “within a single prompt”.
6. Where Things Break
| Friction | Observed Symptoms | AI-Tools |
| Token burn/exhaustion | Test‑case generation balloons to 20 K tokens | • Roo Code (Sonnet 4) • CLine (Gemini 2.5 Pro) • Roo Code (DeepSeek R1) |
| Context loss (via agent’s internal context compression) | • Agent “forgets” specified constraints mid‑chat. • This is the result of the agent internally compressing the prompts given by the user, and sending compressed prompts to the models (which theoretically can/will always have context losses). | Cursor |
| Context loss (via agent reset) | • Agent “forgets” specified constraints and even entire contexts on long chats (possibly including very heavy prompts) due to Agent resets. • This is a result of context resets due to context-window memory saturation on long/context-heavy chats/interactions. | Roo Code |
| Execution misses | • Sometimes, the model ignores explicit instructions. • Either it has to be asked the same requirement again and again with a new prompt each time. • Or it completely ignores and fails to obey even after repeated prompts. • What appears to be the expected output is later found to have missed some subtle but requirements, thereby wasting the review cycle. | • Sonnet 3.7 • Sonnet 4 |
| Hallucination | Incorrect/random facts and outputs are hallucinated. | All models to varying degrees |
| Over‑engineering | • 3 x DB calls for a simple CRON job. • Overly complicated solutions for basic tasks. | Sonnet 4 (irrespective of agent) |
| Getting stuck (When using non-1st-party agents) | • The model keeps suggesting repeated/similar outputs that do not work, and gets “stuck” in a perpetual cycle/loop. • This has been observed (in manual prompts) when trying to generate test cases/features from scratch. • The reason is the lack of rich context support functionality, which is only present in first-party agents like GitHub CoPilot and Claude Code. | When using agents other than Claude Code or other first-party agents from Anthropic: • Sonnet 3.7 • Sonnet 4 |
| Getting stuck (general) | The model keeps suggesting repeated/similar outputs that do not work, and gets “stuck” in a perpetual cycle/loop. | • Sonnet 3.7 • Sonnet 4 |
| Unavailability of extraneous features | MCP servers, agentic prompts etc., may not be compatible with every project. And since they are relatively new, the corresponding attachments, configurations, repositories and/or libraries needed, may not yet be available. | |
| Missing editor features | Presence of token limit-safe tab‑autocomplete in some tools and agents but not in others. | CLine, Gemini CLI |
Workarounds include:
- Prompt splitting: Using intermediate multi-model stage/steps, where initial user prompts are fed to primary models and are meant to achieve action sequence scaffolding/TODOs or instructions generation/prompt writing. Outputs from the primary model are then fed into secondary models
- Manual context refresh: Using compiled context stores/well-curated context seeds, to rehydrate models and quickly initiate new conversations without flooding the context window.
- Strategic model downgrades: Using low-cost, lighter, and faster models for tasks deemed not to require heavier models. This saves token costs & time, and reduces susceptibility to hallucination magnification – (magnification of hallucinations when a single model is used uninspected and unreviewed for a long chat with heavy context window usage).
7. Unlocks We’re Pursuing Next
- Persistent Context – project‑level vector memory or repo‑native embeddings.
- Seamless Multi‑Agent Handoffs – ways to automate and enhance multi-model usage within the IDE.
- Cost Telemetry Estimation – ways to provide an estimate of the token cost that a particular prompt might incur.
- Lean Test Generators – specialized agents tuned for minimal token footprint, lower failure risk, and lower hallucination rates.
8. Recommendations for Other Teams
- Publish prompt strategies and playbooks from your own power users.
- Teach prompt granularity heuristics: filename → issue → constraint → expected output.
- Run a low‑stakes credit swap experiment to expose hidden spend patterns.
- Invest in memory tooling before scaling seat licenses.
9. Appendix
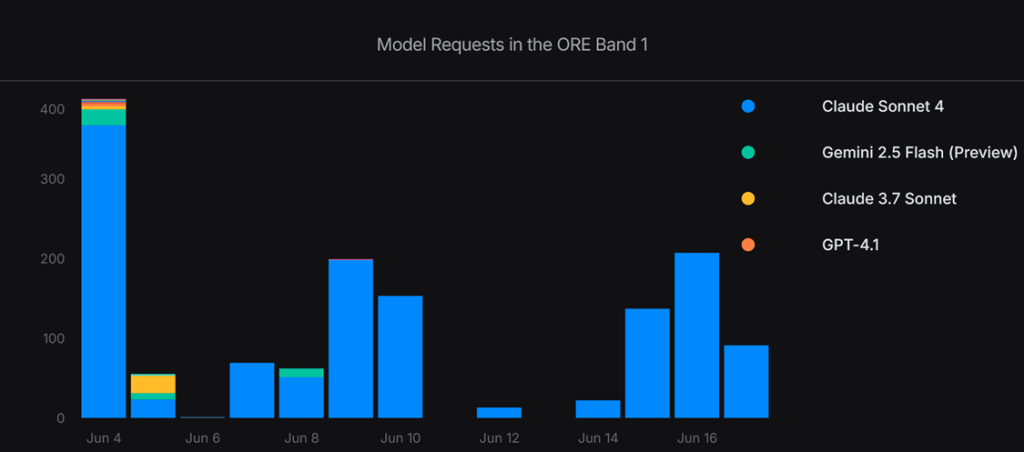
Fig 2. Week-by-week model usage – Visual comparison of models used by power users.
(* The graph doesn’t extend after the day that power devs had exhausted all their credits)
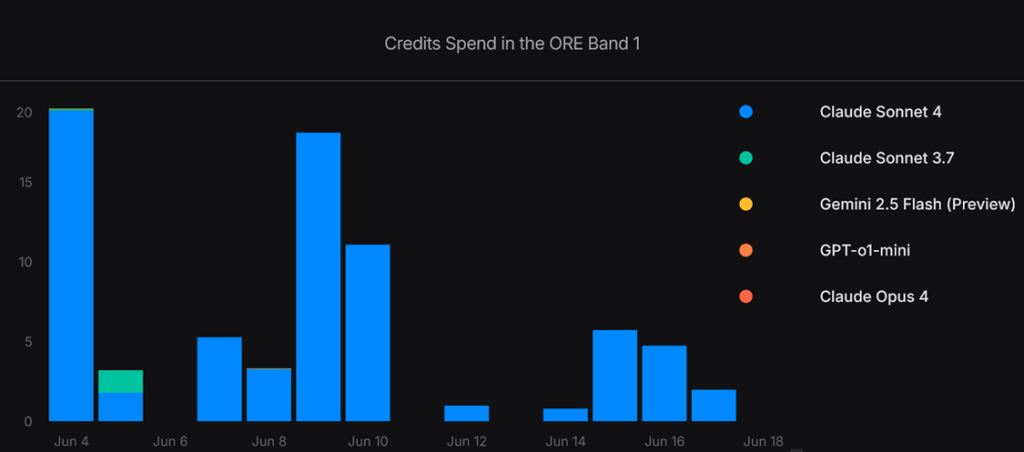
Fig 3. Week-by-week credits usage – Visual comparison of credits spent per model.
The Sonnet series clearly dominates almost the entire credit spend amongst the power users.
10. Closing Thoughts & Next Steps
Our early conclusion: Multi‑model fluency is the strong predictor of AI leverage. The next phase of Project Reboot will expand interviews to lower‑usage cohorts and based on executive decisions, pilot a Claude Pro rollout, subject to stakeholder alignment.
Stay tuned with Shuru Labs- and if you have your own power‑user war stories, feel free to share!
