Hi Folks, We recently encountered a High CPU usage problem on the Production Database. In this blog post, we describe how we designed and implemented the solution to mitigate the problem and make the system highly available.
Let’s get a little familiar with the system 💻
The system comprises 15-20 microservices that are managed using Kubernetes. All of these services use a single instance of a MySQL 5.7 database that stores more than 800 GB of data and serves more than 100 requests per second. And it faced high CPU usage alerts on the database server every 2 to 3 days.
Upon digging into the logs of MySQL and the metrics over newrelic we found slow queries were the main culprit behind the problem. Below is the description of the results achieved by the solution we implemented and the process in between.
Results achieved 📊

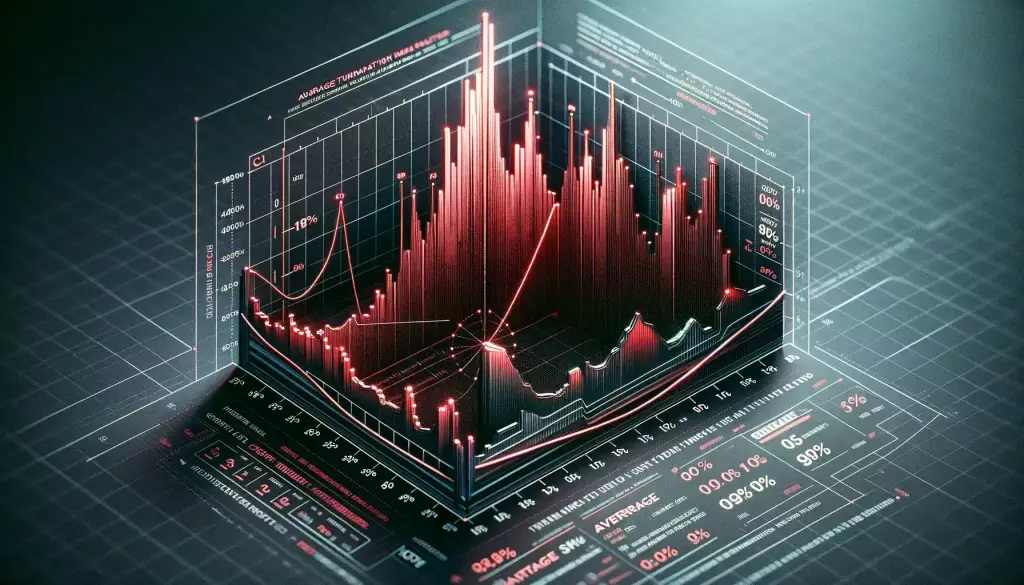
The above picture describes the CPU usage patterns of the MySQL database throughout the implementation of the solution.
Before
- CPU usage % – 87%, 7:45 AM June-6
After
- CPU usage % Max – 40.3% on June 7
- We have not faced any high CPU usage errors on the master database after the migration.
The Process 🪴
Understanding the Environment 🌎
Step one of resolving any problem is getting an in-depth knowledge of the environment of the problem, Let’s review a questionnaire that lists critical questions to answer before drafting a solution.
- Which cloud provider or on-premise solution do we use for our infrastructure, such as AWS, GCP, or any other?
- Describe the overall structure of our infrastructure.
- Do we follow a 1 service 1 database approach or do we use multiple databases for a single service?
- Are we using a single instance of MySQL or do we have multiple instances?
- How frequently do we encounter problems with our infrastructure?
- Is our infrastructure self-hosted or are we utilising a cloud service?
- What version of MySQL are we currently using?
- How many services or workers connect to our MySQL instances?
- What is the size of the data being handled by MySQL? Can you provide information about the VM configuration?
- Do we have information about the query rate per second or minute?
- Can you specify the peak hours and the level of throughput during those hours?
- How critical is this database in terms of business uptime?
- Are all queries slow or is there a particular query that is performing below expectations?
- Do we implement any form of caching for data or API responses to reduce server load?
- How is the backup strategy implemented for our database?
- How do we monitor the database load and infrastructure?
- What actions are taken when the database experiences slowdowns (not downtime, but reduced performance)?
Keeping the answers to the questionnaire in mind, we can now set expectations for the closest-to-ideal solution.
Comparison of Prospective Tools ⚒️
We researched available tools that solved problems aligned with the one we wanted to resolve. There were four prospective solutions we found, namely InnoDB Cluster, Percona XtraDB, Google CloudSQL and Master-Slave Architecture with ProxySQL.
We drafted a comparison matrics comprising of Features (Multi-master Replication Support), Scaling capabilities, Debugging Support availability, Monitoring Support, Hosting options, Disaster Recovery ways, Ease of Setup and Pricing.
| Parameters | InnoDB Cluster | Percona XtraDB Cluster | Cloud SQL | Master-Slaves with ProxySQL |
|---|---|---|---|---|
| Multi-Master Replication | Supported (Group Replication is an eventual consistency system ) | Supported ( the write is either committed on all nodes or not committed at all ) | Not Supported | Not Supported |
| Monitoring Support | MySQL Enterprise Monitoring Dashboard, Third party (e.g Newrelic ) (Paid) | Percona Monitoring and Management (Free) | Cloud Monitoring Dashboard (Free until the certain limit of log amount) | Normal Mysql monitoring will work |
| Hosting Options | Self Hosting | Self Hosting | Hosted Solution over GCP | Self Hosted |
| Disaster Recovery ways | InnoDB ClusterSet | |||
| Ease of Setup | Complex | Intermediate | Easy | Intermediate as ProxySQL is self-maintained component |
| Documentation & Community Support | Stackoverflow questions: 4400 Reddit: mysql community 35.7K Members Medium: very few articles | Stackoverflow questions: 700 Reddit: No Recent Posts Medium: very few articles Reviews: percona customer reviews | Stackoverflow questions: 3800 Reddit: gcloud community 36.6K Members, Active support Medium: Too many articles | Stackoverflow questions: 220 Reddit: proxySQL community Medium: 27 stories about ProxySQL |
| Pricing | Open Source, Estimate | Open Source, Estimate | Paid (Based on Usage), Estimate | Open Source, Estimate |
Considering all the above inputs, some inferences
- The solution should not slow down write operations as we don’t have enough data to say conclusively if the system can handle it. So Percona XtraDB is not something that we can start using.
- Cost is a big point difference between the solutions above, as cloudSQL can be twice as expensive as other solutions. So we cannot start using cloudSQL.
- A single master with multiple replicas is the simplest solution here, it has no logic of master election, quorum and other distributed database complexities.
- So InnoDB cluster with a single primary mode and router to distribute traffic and Master-Slave architecture with ProxySQL are prospectus solutions.
Based on the comparison table and analysis, we chose to move ahead with the Master-Slave architecture with ProxySQL as the solution to mitigate the high CPU usage problem on our MySQL database. This solution offers several advantages, including multi-master replication support, monitoring support, ease of setup, and cost-effectiveness. It provides a simple and efficient way to distribute traffic and handle high loads while ensuring high availability and minimizing the impact on write operations. We believe that this solution will effectively address the CPU usage issue and make our system more stable and scalable.
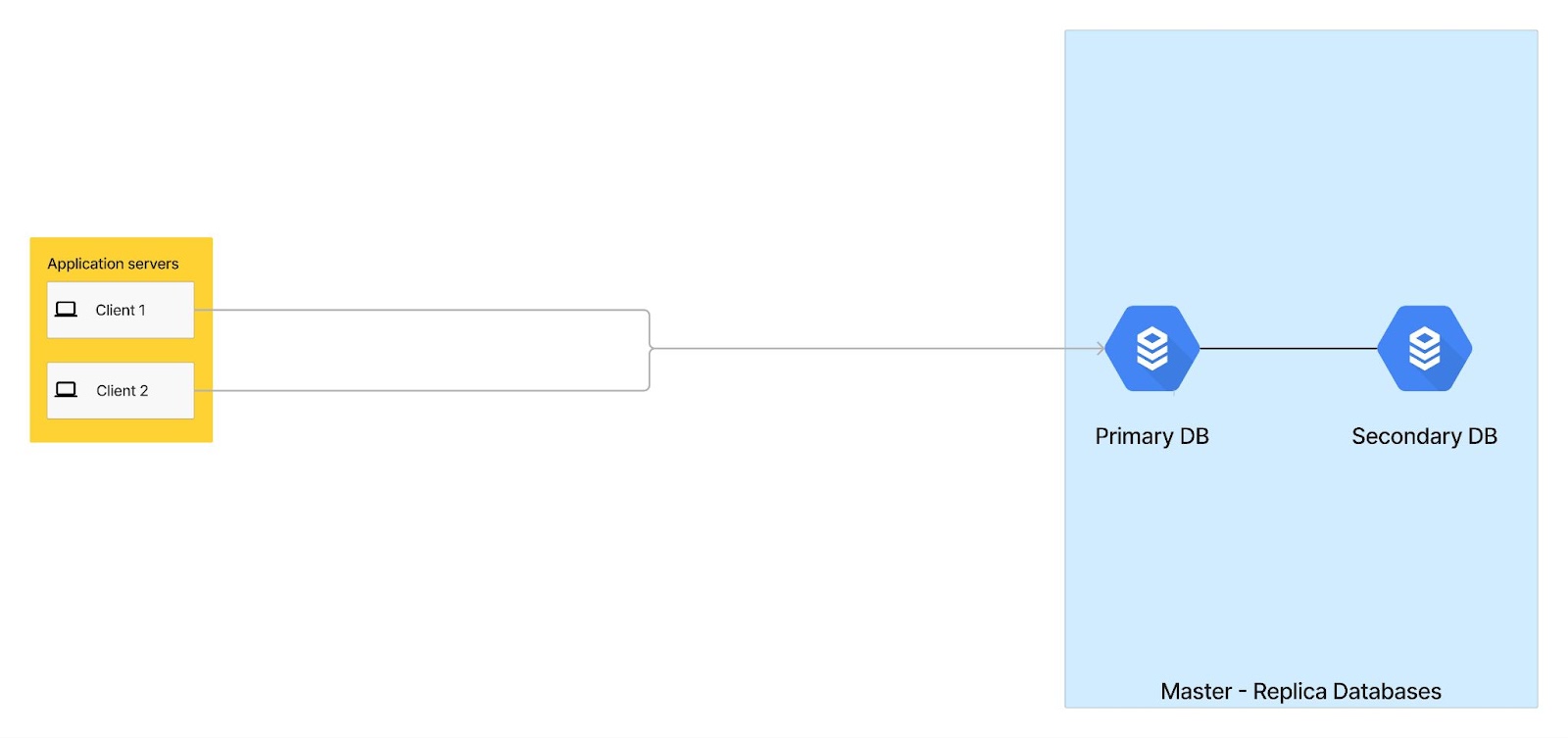
Initial Architecture 👷🏼♀️
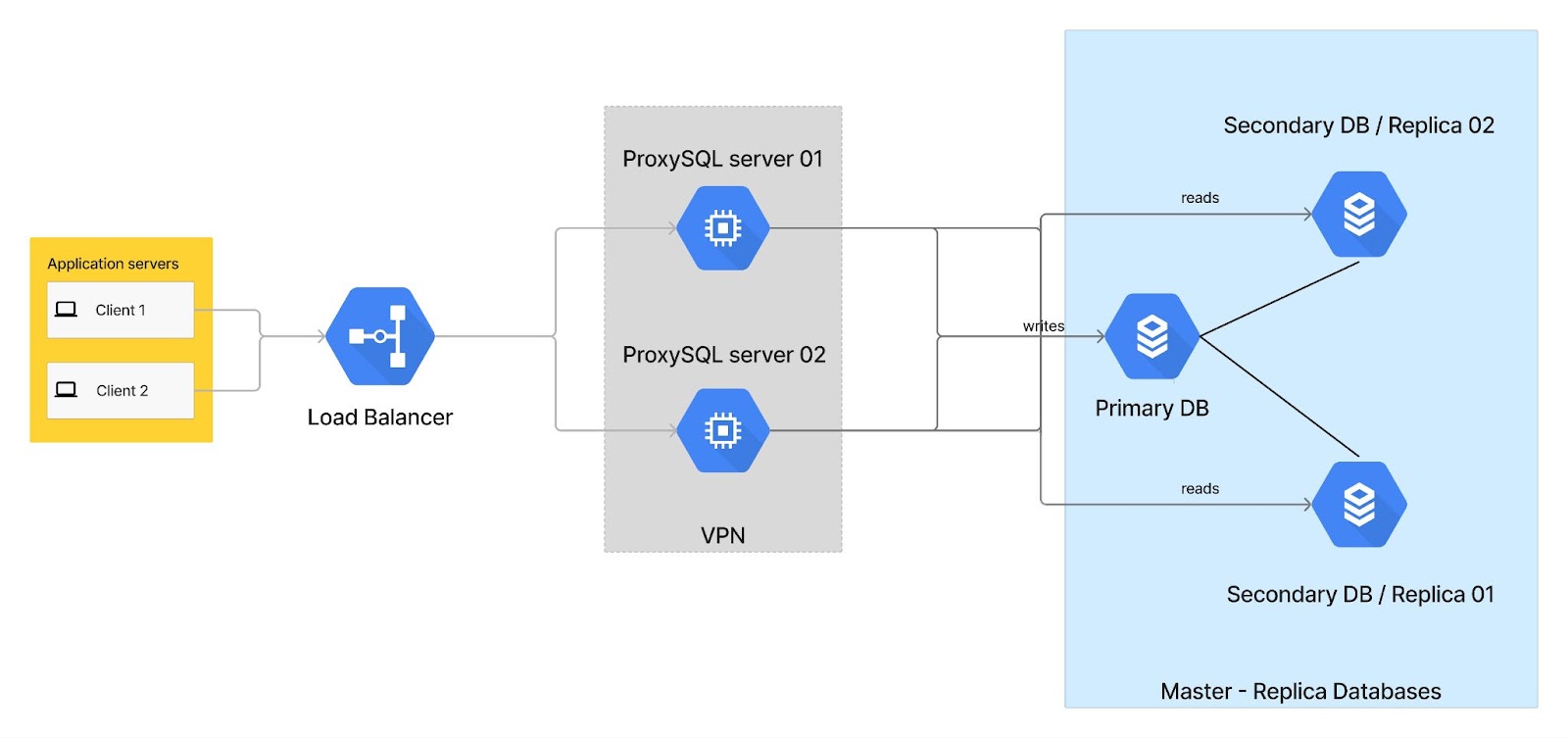
Solution Architecture 👷🏼♀️
Migration Plan 🚢
- Set up replicas for the master database to ensure high availability and data redundancy.
By setting up replicas for the master database, we ensured the high availability of the system. In case of any failure or downtime of the master instance, one replica can take over as the new master, minimising the impact on the system’s availability. This redundancy ensures that the database remains accessible even during unexpected events. - Configure database instances on ProxySQL.
- Implement two instances of ProxySQL to avoid a single point of failure.
To eliminate a single point of failure, we set up two instances of ProxySQL. This redundancy ensures that there is no single point of failure in the database proxy layer, enhancing the overall system’s reliability.
With the implementation of replicas for high availability, ProxySQL for load balancing, monitoring for performance tracking, and the elimination of single points of failure, we have successfully addressed the challenges of high CPU usage on our master database. This solution offers scalability, resilience, and improved query performance, making our system more stable and reliable. - Implement monitoring using Grafana and Prometheus to track important metrics such as CPU usage, query performance, and replication lag.
The implementation of Grafana and Prometheus provided comprehensive monitoring capabilities for our system. We were able to track important performance metrics in real time, identify bottlenecks, and make data-driven decisions to optimize the system’s performance. This proactive monitoring approach helped us identify and address any issues before they could significantly impact the system. - Update the Application Service configuration to connect with ProxySQL instead of the Master database.
Navigate to the file containing the environment variables in the service and update the following to ProxySQL Load Balancer IP and Port respectively- DB_HOST
- DB_PORT
- Add query rules to ProxySQL to redirect slow reads to the replica instances one by one.
This helps offload the workload from the master database and improves overall query performance.
Rollback Strategy ⏪
The above migration plan had a single-step rollback i.e. updating the application configuration back to the original or simply reverting changes made in step 5 of the Migration Plan.
The rollback step should be one of the pivots of any migration strategy. A rollback strategy is a crucial aspect of any system implementation or migration plan. It outlines the steps to revert to the previous state in case of unexpected issues or failures. The importance of a rollback strategy cannot be overstated, as it provides a safety net and minimises potential downtime or data loss.
Having a well-defined rollback strategy ensures that the system can quickly and efficiently revert to its previous state, mitigating any negative impact on the business operations. It allows for a smooth transition back to the original configuration and minimizes disruptions to users or customers.
When designing a rollback strategy, it is essential to consider the following:
- Checkpoints: Define specific checkpoints throughout the implementation process where the system’s state is saved. This allows for easy identification and restoration to a known stable state if needed.
- Backups: Ensure that backups of critical data and configurations are taken before proceeding with any changes. These backups should be easily accessible and validated for integrity.
- Documentation: Document the steps involved in the rollback process in detail. This documentation should be easily accessible to the team members responsible for executing the rollback.
- Testing: Test the rollback strategy in a controlled environment to verify its effectiveness and identify any potential issues or dependencies that may arise during the rollback.
- Communication: Communicate the rollback strategy to all relevant stakeholders, including the team members involved in the implementation, management, and support of the system. Clear communication ensures everyone is aware of the process and understands their roles and responsibilities in case a rollback is required.
By having a comprehensive rollback strategy in place, you can minimise the impact of any unexpected issues or failures during system changes. It provides confidence to the team and stakeholders, knowing that a well-defined plan is in place to revert to a stable state if needed.
Next Steps 🪜
In the above approach as discussed, we mitigated High CPU Usage by using a read split feature provided by a tool ProxySQL and made the system more Highly Available. But the Slow Queries still exist as it is, and if the system continues to have more such queries soon the system might bloat again, and we would have to add more resources to mitigate the immediate problem.
So the next step should be to resolve the Slow Queries, we will be soon writing about our take on it. Stay tuned.
Further Reads 📙
ProxySQL Setup Wiki: https://shurutech.com/comprehensive-step-by-step-proxysql-guide/