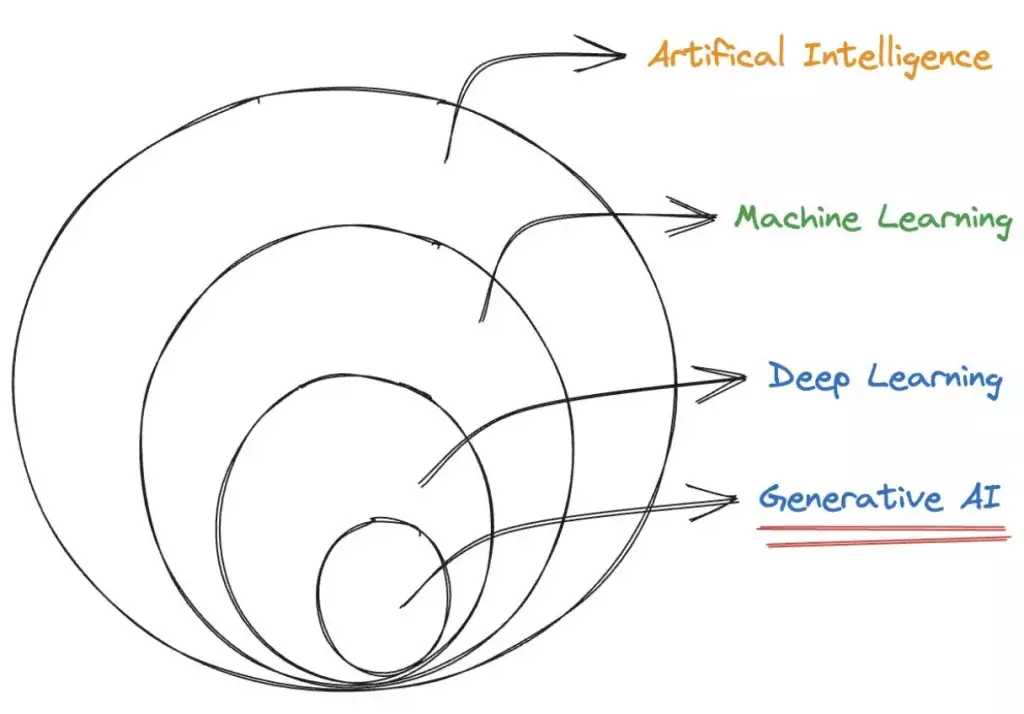
Artificial Intelligence (AI) has revolutionized numerous fields, from healthcare and finance to transportation and entertainment. With its ability to mimic human intelligence and perform complex tasks, AI has become an indispensable tool in our modern world. One intriguing and rapidly evolving aspect of AI is generative AI, a subfield that pushes the boundaries of creativity and imagination.
In this blog, we will delve into the fascinating world of generative AI. Throughout this journey, we will provide an overview of generative AI, explore the technical terms, models, and techniques that enable human-like behaviour from machines, and delve into the principles and ethics that guide responsible AI development. Join us as we uncover the wonders of generative AI.
Moving forward we need to understand where the Generative AI fits in.
Table of Contents
Generative AI
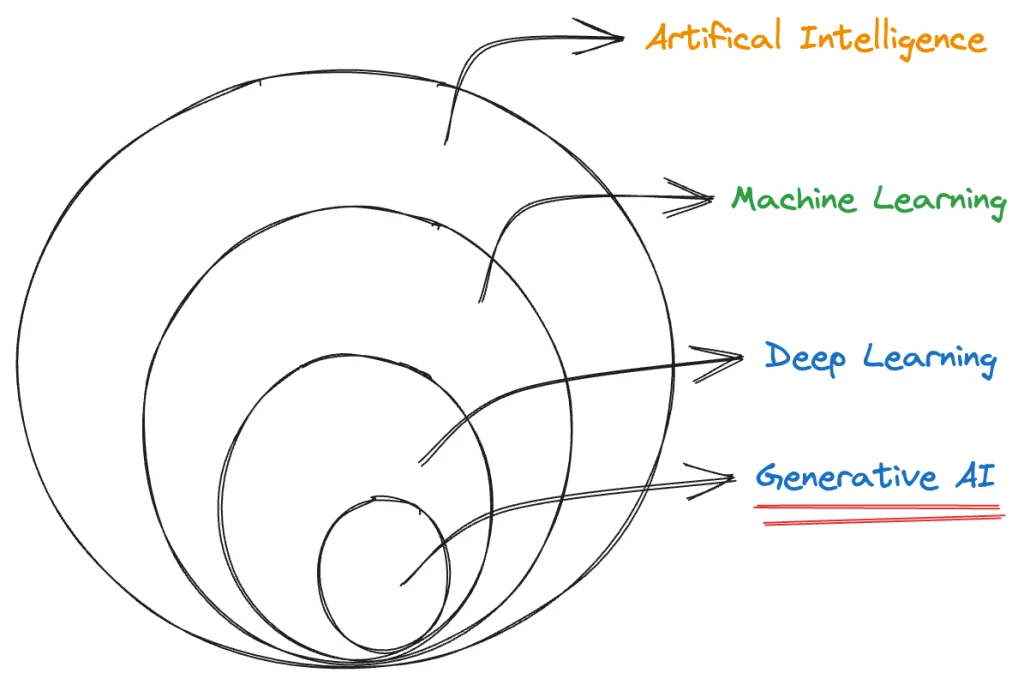
Generative AI, a subset of deep learning, can generate new data instances based on its understanding of existing content. In the realm of text prediction, generative models learn the intricacies of language from training data and utilise this knowledge to complete sentences. The efficacy of generative AI heavily relies on the quality and diversity of the training data fed into the model, enabling it to discern patterns and structures in the input data and learn from them.
By harnessing the capabilities of artificial neural networks, generative AI can process both labelled and unlabeled data. It employs a range of techniques, including supervised, unsupervised, and semi-supervised learning, to derive meaningful insights.
Through the power of generative AI, we unlock a realm of creativity and innovation, expanding the horizons of what machines can achieve in content creation and manipulation.
We use Deep Learning Models to perform these tasks. These models play a pivotal role in classifying, predicting, and generating new content such as images, audio, and video from text. To categorize them effectively, we can distinguish between two main types:
- Discriminative Models: These models are trained using labelled data and excel at classification and prediction tasks. They focus on discerning patterns to make informed decisions.
- Generative Models: In contrast, generative models are trained on both labelled and unlabeled data, enabling them to create entirely new content. They have the remarkable ability to generate fresh text, images, videos, and more.
Let’s understand from the example.
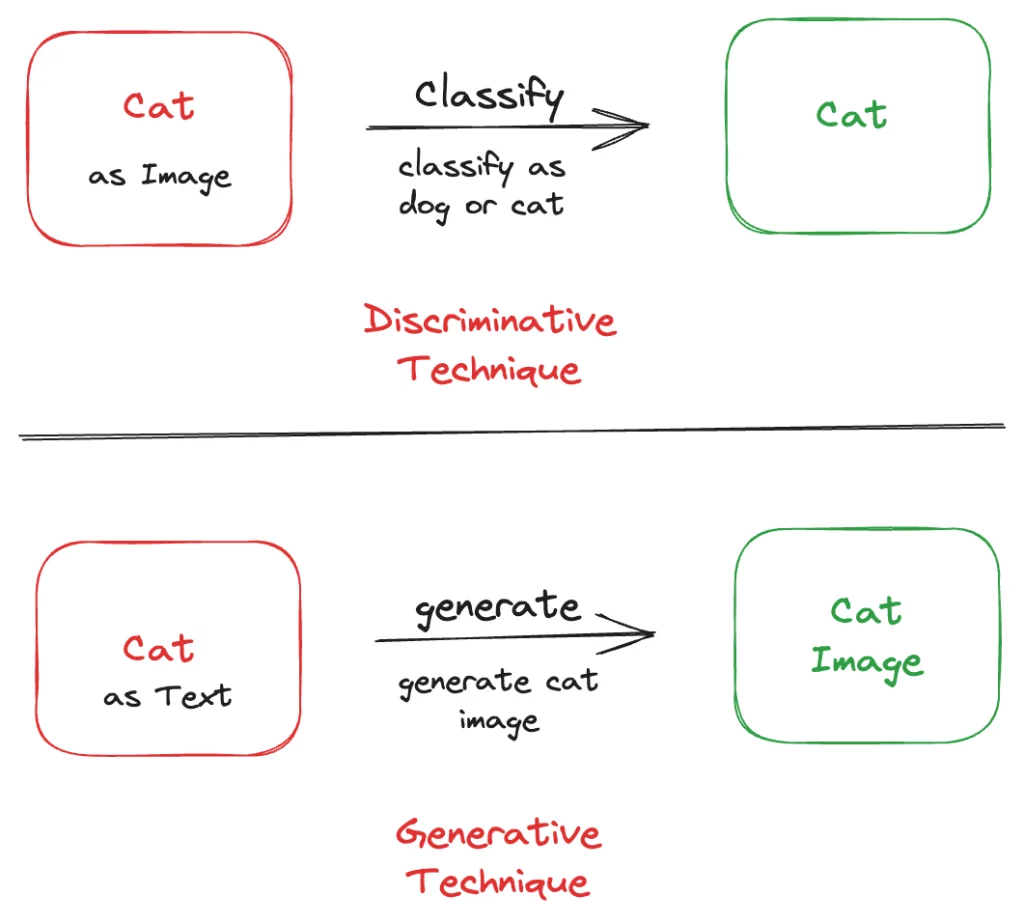
In the diagram depicted above, we observe the utilization of discriminative techniques, employing discriminative models to classify the given input. Initially, the model undergoes training using labelled data, enabling it to classify subsequent inputs accurately. In practice, an image is passed through the model, and based on its learned knowledge, the model classifies the image and produces a corresponding response.
Contrarily, in the generative technique, the text is employed to generate an image of a cat. By providing a textual description, the model harnesses its generative capabilities to create an image that encapsulates all the mentioned details.
Through these distinct approaches, discriminative and generative techniques unlock novel possibilities within the field of artificial intelligence, offering diverse methods to classify and generate content based on different types of input.
Now, let’s discuss some of the technical terms associated with Generative AI.
Hallucinations
Hallucinations in AI occur when a model produces outcomes that deviate from the expected or desired results. These are instances where the generated outputs lack coherence, contain grammatical errors, or even provide inaccurate and misleading information.
Several factors can contribute to the occurrence of hallucinations, including:
- Noisy or Dirty Data: If the model is trained with data that contains errors, inconsistencies, or misleading information, it can negatively impact the quality of the generated results, leading to hallucinations.
- Insufficient Training Data: When the model is not exposed to a sufficient amount of diverse and representative data during the training phase, it may struggle to generalize and produce coherent outputs. In such cases, limited exposure to various patterns and contexts can contribute to hallucinations.
- Lack of Context: Context plays a crucial role in understanding and generating meaningful outputs. If the model is not provided with enough contextual information or fails to consider the broader context, it may generate outputs that lack relevance or coherence.
Identifying and addressing the underlying causes of hallucinations is essential in improving the reliability and quality of AI models. By ensuring clean and representative training data, increasing the volume and diversity of the training dataset, and providing sufficient contextual information, we can mitigate the occurrence of hallucinations and enhance the overall performance and accuracy of AI systems.
Prompt, Prompt Design and Prompt Engineering
The prompt serves as a vital piece of text that acts as the input to the model, ultimately influencing the output it generates. Prompt Design encompasses the art and science of crafting a well-designed prompt that elicits the desired response from the model.
Prompt Design involves careful consideration of the wording, structure, and context provided to the model. By tailoring the prompt to the specific task or objective, we aim to guide the model towards producing relevant and accurate outputs. It is a meticulous process that requires an understanding of the model’s capabilities and limitations, as well as the nuances of the desired task.
Prompt Engineering plays a crucial role in maximizing the efficiency and effectiveness of language models across a diverse range of applications. It involves the practice of developing and optimizing prompts to leverage the full potential of LLMs for various tasks. Prompt Engineering encompasses techniques such as prompt tuning, prompt augmentation, and prompt concatenation, among others, to fine-tune and optimize the prompt-input pipeline.
By investing time and effort into the prompt design and prompt engineering, we can harness the power of LLMs more effectively, ensuring that the outputs align with the desired objectives. These practices contribute to LLMs’ overall performance and utility in diverse applications, empowering us to leverage their capabilities for improved natural language processing, understanding, and generation.
Model Types
A diverse range of models is employed to generate outputs based on the provided prompts. These models undergo extensive training on vast amounts of data, enabling them to exhibit remarkable capabilities.
Let’s explore the various types of models utilized in this context:
- Text-to-Text: These models excel in generating text-based outputs in response to textual prompts. They can be employed for tasks such as language translation, summarization, question answering, and text generation.
- Text-to-Image: With the ability to generate images based on textual inputs, these models bridge the gap between language and visual representations. They can create visual content that aligns with the description provided in the text prompt.
- Text-to-Video: Operating at the intersection of text and video, these models have the capacity to generate video content based on textual input. They bring together the power of language and moving imagery, enabling the creation of dynamic visual sequences.
- Text-to-3D: These models unlock the potential for generating three-dimensional (3D) objects or scenes based on textual descriptions. By leveraging text prompts, they can produce 3D models, architectural designs, or virtual environments.
- Text-to-Task: With a focus on task-oriented outputs, these models generate results that align with specific tasks or actions. By understanding and interpreting textual prompts, they can perform actions such as booking reservations, providing recommendations, or executing commands.
These models represent the remarkable convergence of language and various modalities, enabling AI systems to generate outputs in different formats and domains. By harnessing the power of text and leveraging their training on extensive datasets, they pave the way for innovative applications across a wide range of fields.
Large Language Models
Large Language Models (LLMs) represent a subset of deep learning models that offer exceptional versatility and proficiency in a wide range of natural language processing (NLP) tasks. These models can be pre-trained and fine-tuned to serve specific purposes, making them a powerful tool in the field of NLP.
LLMs undergo pre-training using extensive datasets, comprising a significant number of parameters. During pre-training, the models learn to predict the next token in a given context, effectively capturing the intricacies of language and context. This process is repeated multiple times to achieve a satisfactory level of accuracy.
Furthermore, LLMs possess the capability to perform various NLP tasks. They can generate and classify text, engage in conversational question answering, and even facilitate language translation from one language to another. This versatility arises from their ability to understand and manipulate language in a meaningful way.
To enhance their performance, LLMs can be fine-tuned for specific tasks. Fine-tuning involves adapting the pre-trained models to cater to a particular type of task, optimizing their performance and accuracy in that specific domain.
The architectural backbone of LLMs is transformers. LLMs leverage the power of transformers, which are deep learning models specifically designed to handle sequential data, by capturing intricate relationships and dependencies within the input text. The transformer architecture, with its self-attention mechanism, enables LLMs to effectively process long-range dependencies and contextual information, resulting in superior language understanding and generation capabilities. Together, LLMs and transformers have revolutionized natural language processing tasks, empowering machines to comprehend, generate, and manipulate human language with remarkable fluency and accuracy. You can read more about transformers here.
Example: We can train a dog to do everyday stuff like sit, come, down, and stay. Now the dog which is used for military purposes, got the training for the specific purpose i.e., we are going to fine-tune it. We can also do the same for the LLMs.
The diagram below shows where the LLM fits in the standard diagram.
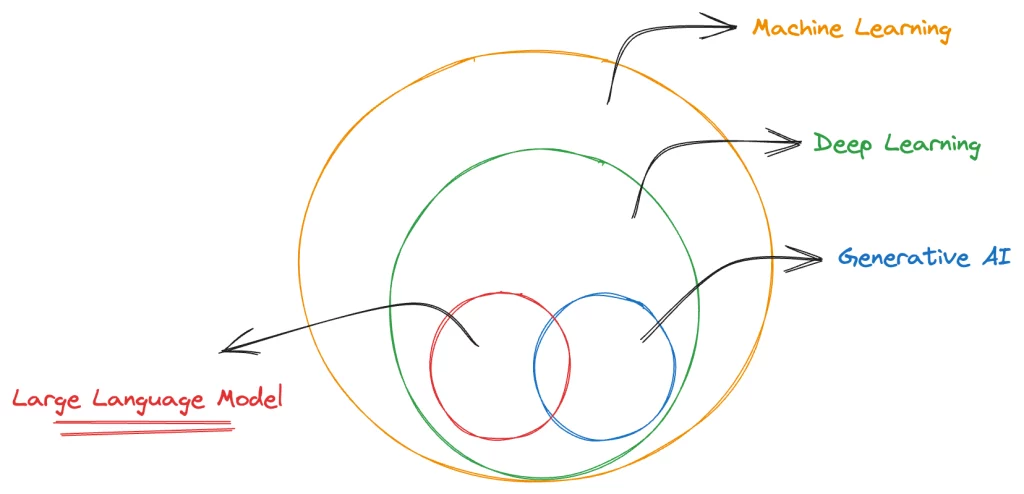
Benefits of using the LLMs
- The single model can be used for different tasks. This is because these models are trained on petabytes of data and generate billions of parameters that can be used for language translation, sentence completion, question answering and more.
- The LLMs require minimum training data when we fine-tune them for specific purposes. Through the initial pre-training on vast amounts of data, LLMs develop a strong foundation of language understanding. This pre-training allows them to grasp general linguistic patterns, structures, and contextual cues. Consequently, when fine-tuning LLMs with task-specific data, they efficiently leverage the knowledge acquired during pre-training, resulting in impressive performance even with limited training examples. This characteristic highlights the efficiency and effectiveness of LLMs, enabling us to achieve desired outcomes with relatively small amounts of task-specific training data.
- The performance of the model grows when we introduce more data to the model. By increasing the volume of data used for training, the model becomes exposed to a wider range of examples, patterns, and variations, allowing it to learn more effectively and make better predictions. The additional data helps the model capture a more comprehensive understanding of the underlying patterns and relationships within the data, leading to enhanced performance and improved accuracy. This iterative process of incorporating more data enables the model to continuously refine its knowledge, adapt to different scenarios, and produce more reliable and meaningful outputs.
An example of LLM is PaLM, Pathways Language Model, introduced by Google in April 2022. It has 540 billion parameters that can be used for different purposes and tasks. It is a transformer model.
Responsible AI
Since our introduction to AI, we are using it in most of our tasks and it helps us to do work efficiently but everything has its pros and cons. To make AI safe and trustworthy, google introduced the AI principle which they follow while inventing anything with the help of AI.
These principles revolve around the standard fields are Transparency, Fairness, Accountability and Privacy. So, it’s important that you have a defined and repeatable process for using AI responsibly.
The 7 AI principles introduced by Google are:
- AI should: Be socially beneficial
- AI should: Avoid creating or reinforcing unfair bias
- AI should: Be built and tested for safety
- AI should: Be accountable to people.
- AI should: Incorporate privacy design principles
- AI should: uphold high standards of scientific excellence
- AI should: Be made available for uses that accord with these principles
At last, we recommend you explore some of the freely available Generative AI learning resources like the one offered by Google and the Short Courses offered by DeepLearning.AI (A company founded by Andrew Ng).
So these are some of the points we should keep in mind while creating something using AI.